Create a Location Generator GAN

TL;DR
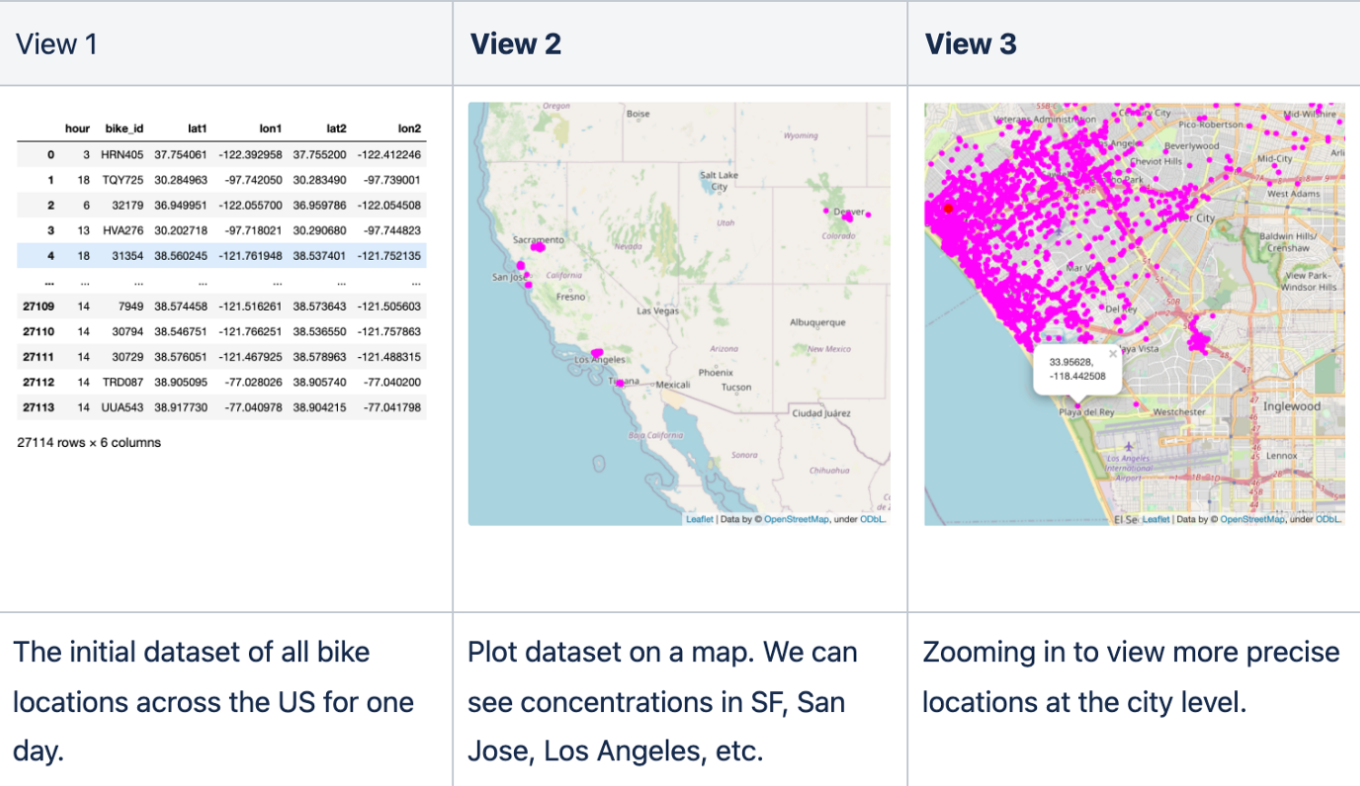
Generating realistic location data for users for testing or modeling simulations is a hard problem. Current approaches just create random locations inside a box, placing users in waterways or on top of buildings/etc. The GAN location generator we created can use map data to predict where a human (or e-bike in this case) might be, for any location in the world.
Introduction
In this post, we will explore training a FastCUT Generative Adversarial Network (GAN) model on map data and public e-bike feeds from cities across the USA. We can then test the model’s ability to learn and generalize by predicting location data sets for cities across the world, including Tokyo. If you’d like to follow along, clone the example repo from GitHub 👇 and create synthetic location data sets for your own city!
In a previous blog, we trained a LSTM-based language model on precise location data from e-bike feeds, and used the model to generate synthetic and privacy-enhanced datasets for the same regions (e.g. Santa Monica, CA). By framing the problem differently and incorporating map data for context, we can create a model that generates precise locations that humans might visit for locations across the world.
Getting Started
We can model this by encoding e-bike location data as pixels into an image, and then training as an image translation task similar to CycleGAN, Pix2pix, and StyleGAN. For this post, we’ll use the newer contrastive unpaired translation (FastCUT) model that was created by the authors of pix2pix and CycleGAN as it’s memory efficient, fast for training (useful for higher-res locations), and generalizes well with minimal parameter tuning. Follow along or create synthetic location data for your own city with the complete end-to-end example on GitHub https://github.com/gretelai/GAN-location-generator.git
Steps
Model training steps
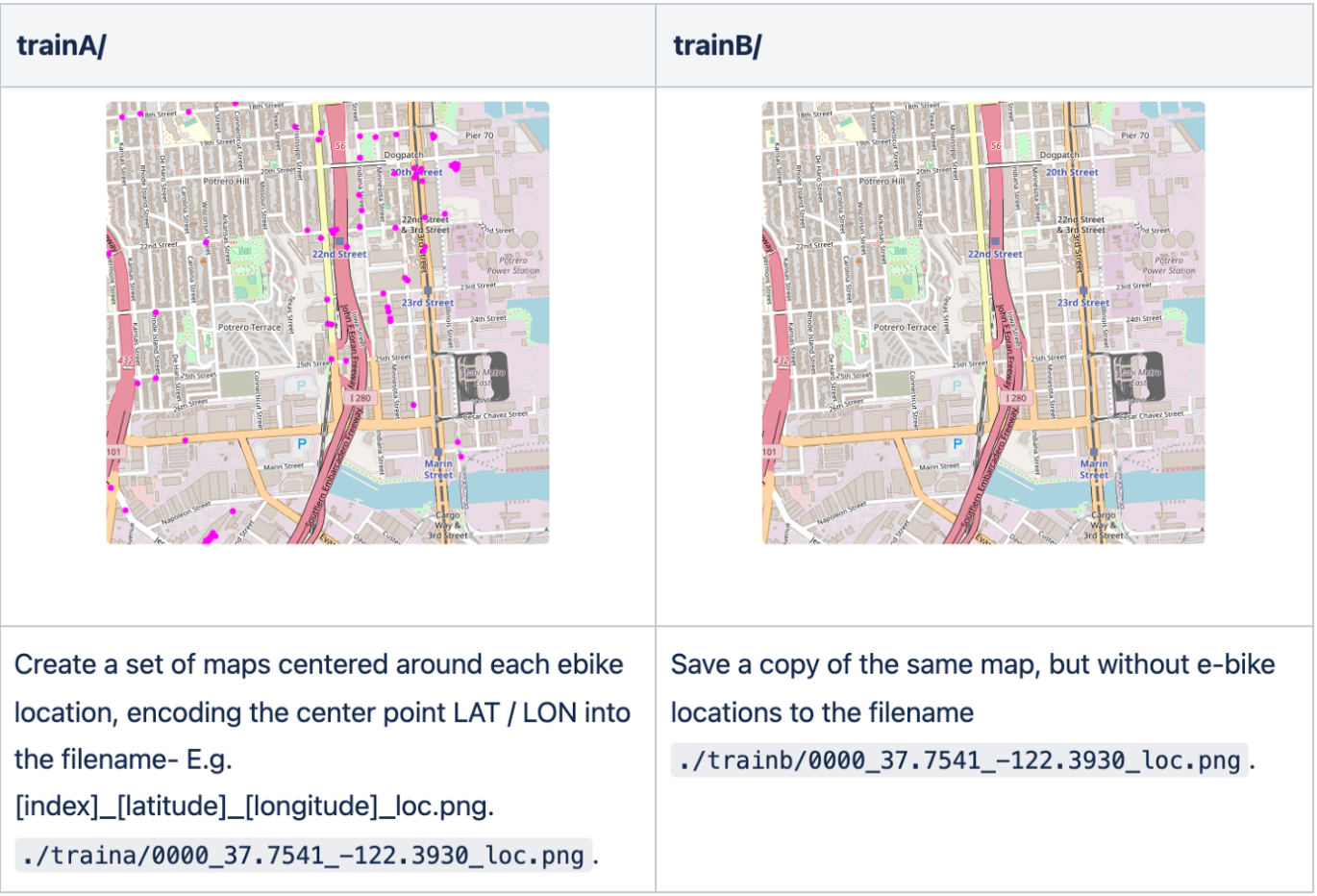
- Create DomainA from a corpus of precise e-bike locations on a map
- Create DomainB from the same maps, but without locations
- Train FastCUT on translating DomainB → DomainA
Synthetic data generation steps
- For a target geographic location, download new maps (DomainC)
- Run inference on the FastCUT model to predict scooter locations (translate DomainC->DomainA)
- Process images using CV to find scooter locations and convert to LAT/LON
Create the training dataset
After installing dependencies, run python -m locations.create_training_data to create pairs of 512x512px map images with and without location data from the e-bike dataset.
Next, train our model on the dataset- essentially training the FastCUT model to predict where e-bike locations would be given a map.
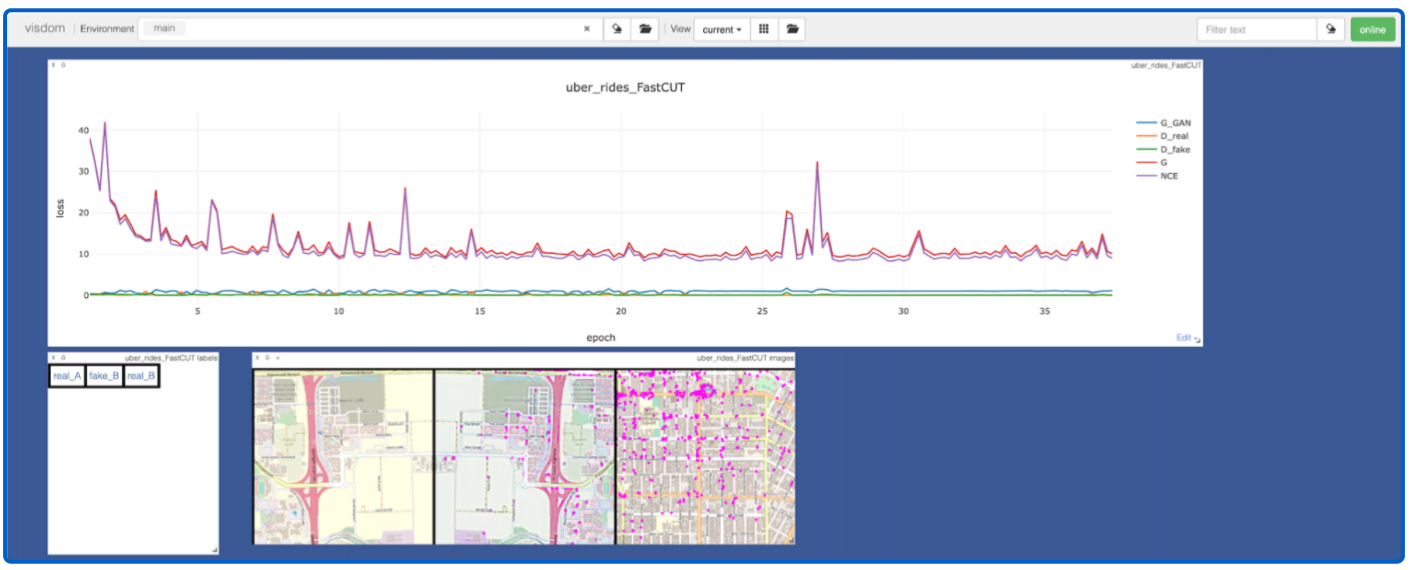
The FastCUT model logs data to Visdom, which lets us monitor model training. In the plot below, we can see both model losses decreasing during training, and also a preview of the image translation task. The first image is the real DomainA map data, the second is a flipped version of the DomainA image with predicted scooter locations (fake), and the third being the real DomainB locations. We can see that even after 25 epochs, the model is learning to predict what look like reasonable scooter locations- e.g. street corners and along roads.
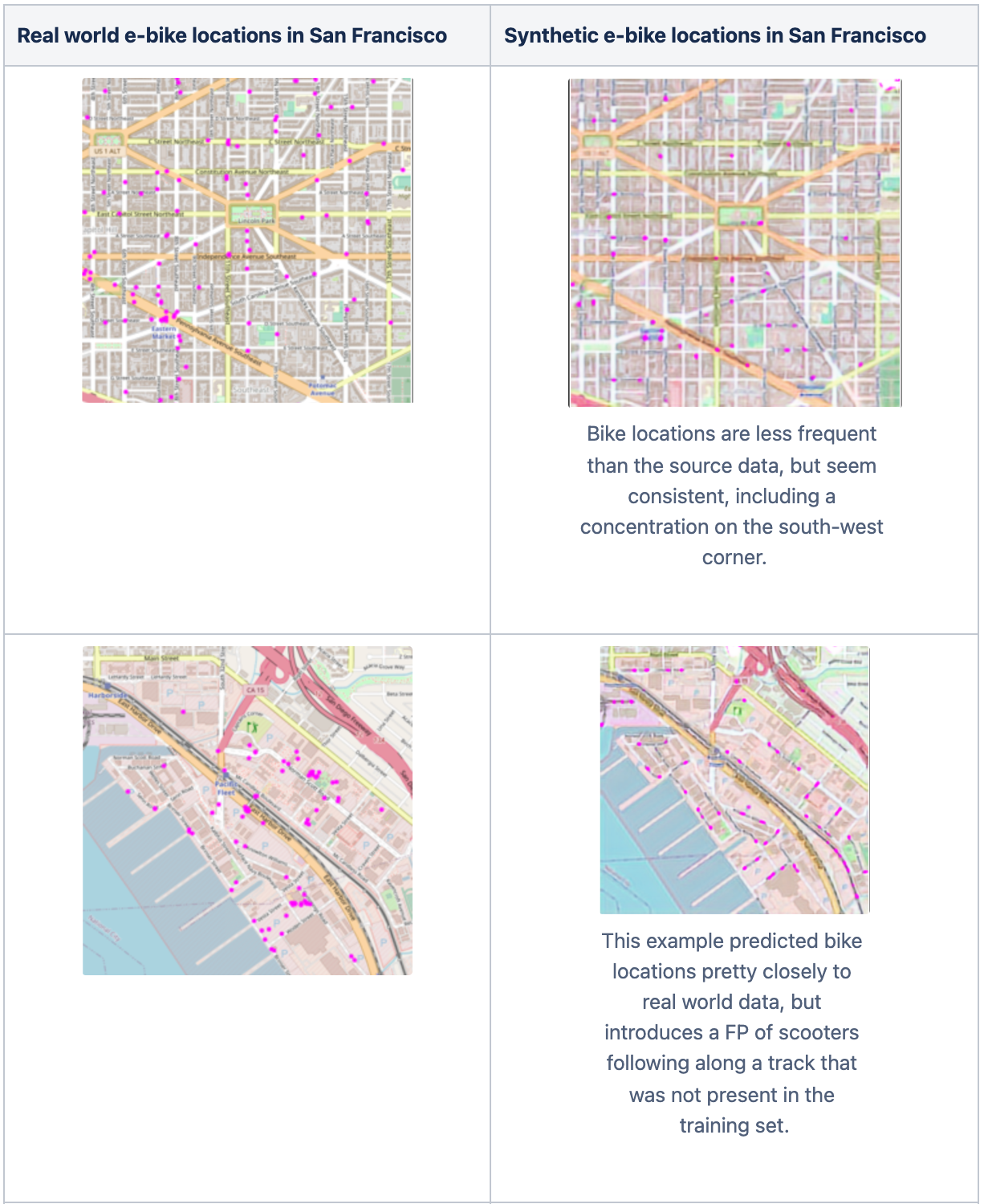
The model seemed to overfit when running for the recommended 200 epochs, with predicted scooter locations disappearing from images. For this example, I saw the best performance in earlier epochs (epoch 30). Here are some real world v. synthetic images from San Francisco that were predicted by the model.
Create the test dataset
Run the command below to create a training dataset of a 15x15 grid of the map locations in downtown Tokyo, or modify the latitude and longitude parameters to create synthetic locations for any geographic region. Note that with how the FastCUT python code works, we’ll need to copy the map grid images both into the testA and testB directories.

We can now use our model to process each of the images created for the grid above to predict e-bike locations across Tokyo.
Looking at the results of individual images:
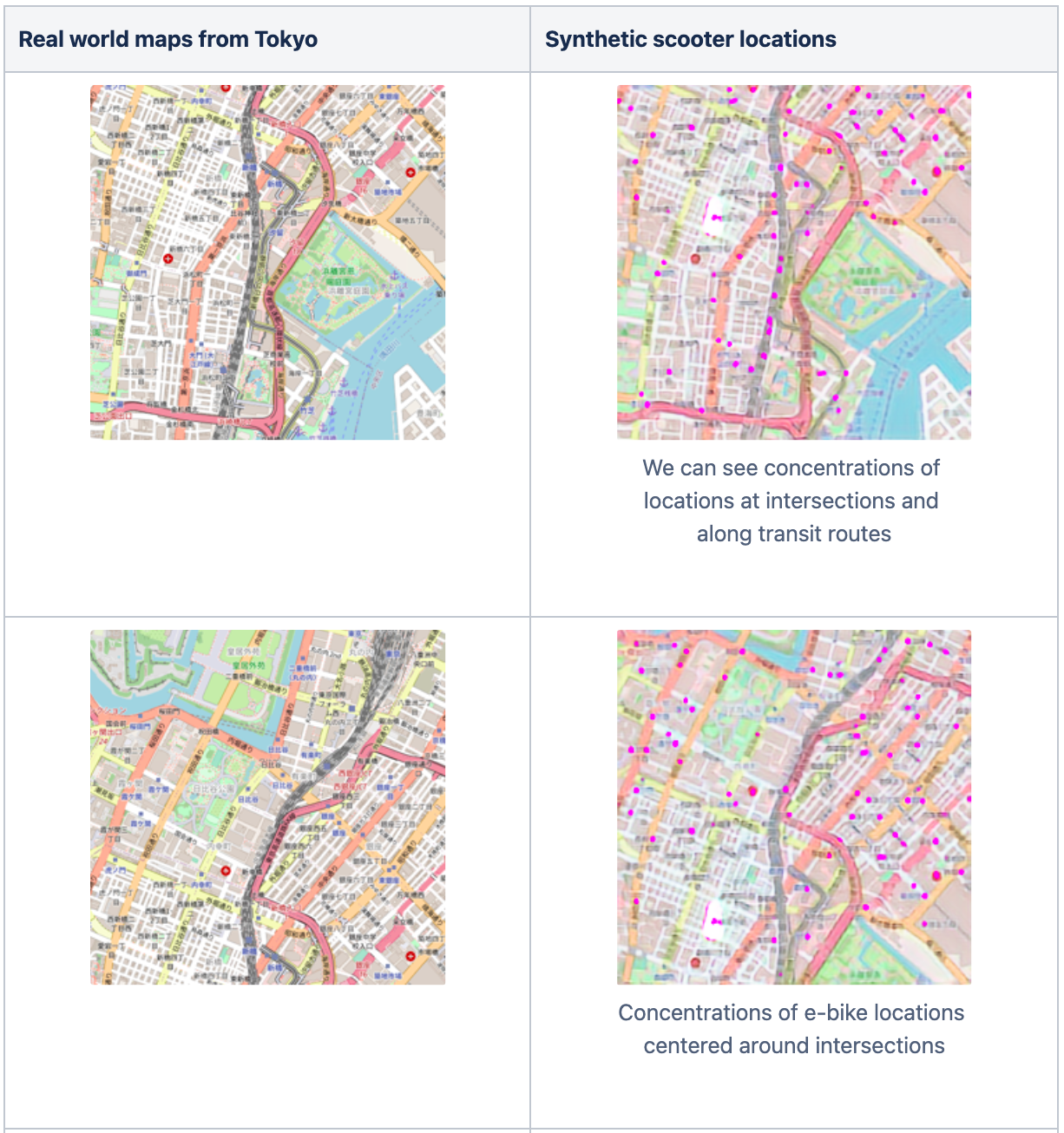
Converting synthetic images back to coordinates
Now our task is to take the synthetic e-bike in our images from Tokyo and convert them to real-world coordinates to build our synthetic location dataset. To extract the e-bike locations, we apply an image mask using OpenCV that searches for any groups of magenta-colored pixels in the image. Once the mask is created, we can calculate what the distance is for any pixel in the mask from the center-point latitude and longitude that is encoded in the image file name.
Note that depending on where the city is in the world, the physical distance between each latitude or longitude degree can vary significantly, and we will need to use an ellipsoid-based model to calculate precise offsets when mapping pixels to locations. Fortunately, the geopy Python library makes this easy.
The image below uses the cv2.imshow() function to preview the masked image that we then convert back into latitude and longitude coordinates.
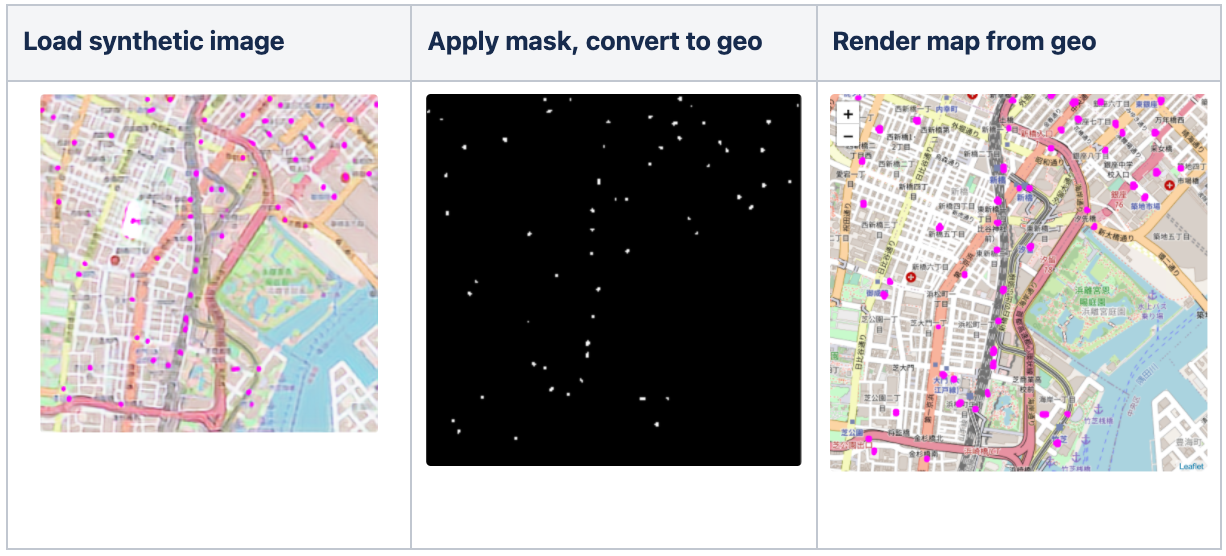
Putting it all together
We can now process all images and stitch the synthetic locations into a new dataset for all of Tokyo.
There are some definite false positives when viewing data across Tokyo, particularly with locations being generated for waterways. Perhaps further model tuning, or providing more negative examples of waterways in the training data (domainA or domainB) would reduce false positives.
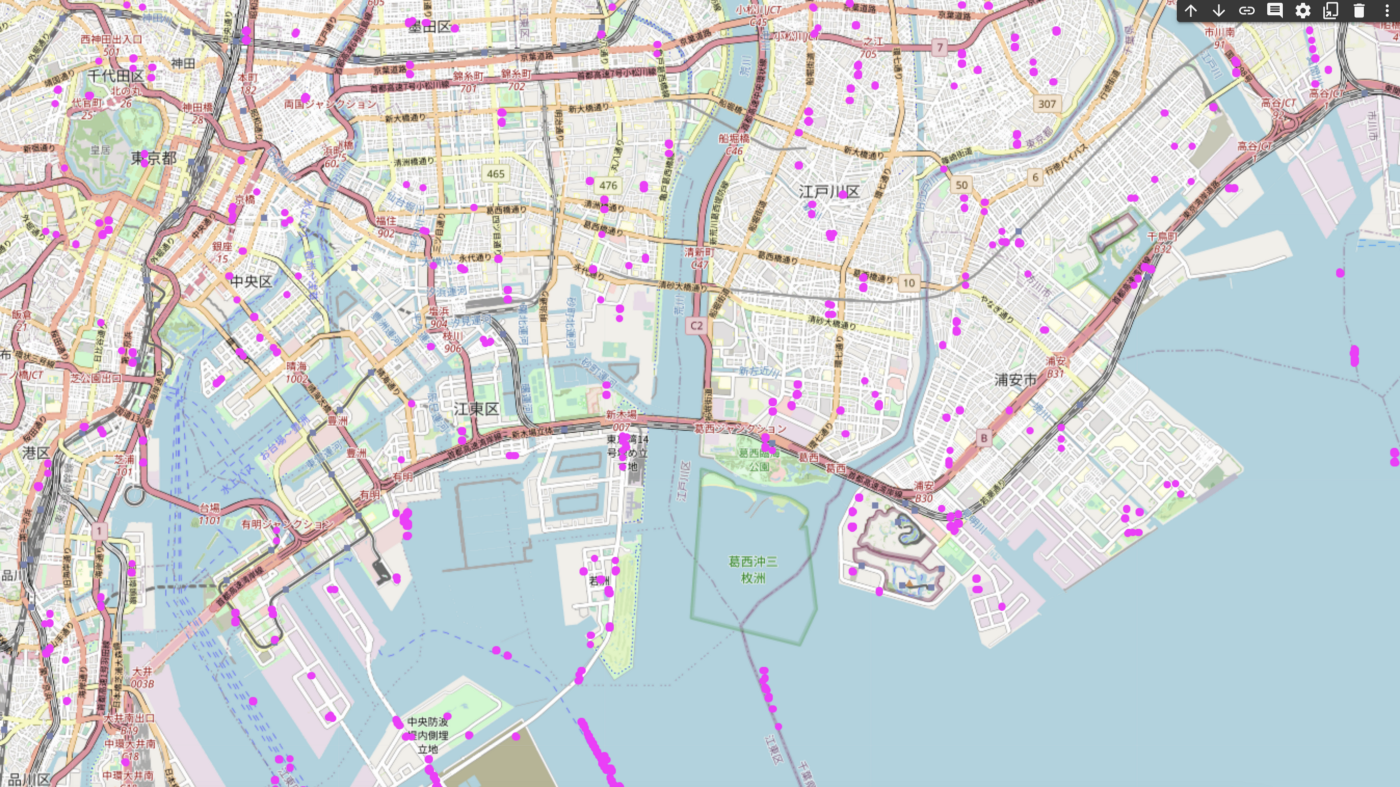
However, results are encouraging (given little model or dataset tuning)- with the model seemingly able to mimic the distributions and locations of the e-bike dataset that was trained on using maps from a different part of the world.
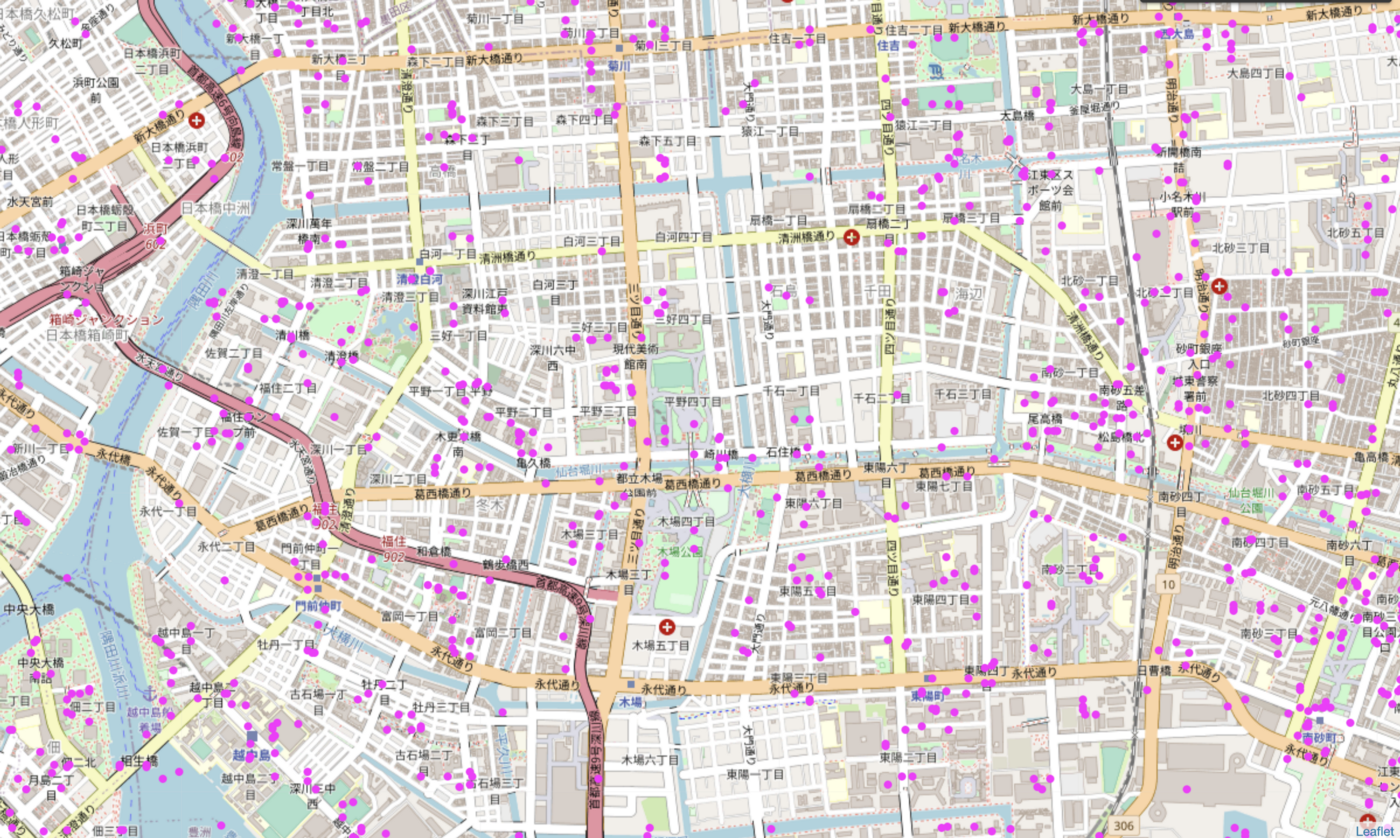
Conclusion
In this post we have experimented with applying context from the visual domain (e.g. map data) along with tabular data, to create realistic location data for anywhere in the world. Please leave a ⭐️ on GitHub, or let us know on our Slack if you like this example or have any questions!
Credit
Credits to the authors below for their excellent paper and code on the FastCUT algorithm that we applied for this example. https://arxiv.org/pdf/2007.15651 by Park, Efros, Zhang, Zhu (2020).


