Using generative, differentially-private models to build privacy-enhancing, synthetic datasets from real data.
Introduction
Open datasets are incredibly valuable for democratizing knowledge, and enabling developers and data scientists to experiment with and use data in new ways. Whether the datasets contain location data, imagery (such as security camera video), or even movie reviews, the underlying data used to create these datasets often contains and is based on individual data.
The cornerstones of modern privacy regulations (such as Europe’s GDPR, and California’s CCPA), and also privacy-enhancing technologies such as differential privacy and k-anonymity, are centered on protecting the privacy of individual users within a dataset.
Anonymizing data
To release datasets to the world, developers and data scientists have traditionally employed a set of techniques to maintain the statistical insights of data, while reducing the risk of individual users personal data being revealed. These techniques are applicable anywhere from protecting highly sensitive data, such as an individual user’s medical condition in a medical research dataset, to being able to track an individual users locations in an advertising dataset. Common techniques include data anonymization (for example, masking or replacing sensitive customer information in a dataset), generalizing data (bucketing a distinguishing value such as age, or satisfaction scores into less distinct ranges), or perturbing data (inserting random noise into data such as dates to prevent joining with another dataset). More advanced and cutting edge techniques, such as differential privacy, offer formal guarantees that no individual user’s data will affect the output of the overall model.
Let’s explore whether we can apply a combination of machine learning and differential privacy to further enhance individual user privacy. This approach has the potential benefit of being less prone to human error than the manual techniques described above. It also increases flexibility with the ability to generate new datasets of any size, and offers formal mathematical guarantees around privacy.
To test our theory, we’ll train a generative, probabilistic neural network on a public ride-sharing dataset, and then attempt to create both synthetic, and differentially private synthetic datasets of the same size and distribution. The goals is to see if synthetic (artificially generated) data can provide nearly the same usefulness and statistical insights as the original dataset, with enhanced protection for individual privacy. In part 2, we’ll dive into baking off our newly generated synthetic and private datasets against the source data on several data science challenges.
Diving into the ride share dataset
We’re going to train, and build our synthetic dataset off of a real-time public feed of e-bike ride-share data called the GBFS (General Bike-share Feed Specification). This data is often shared with municipalities to help with city planning and understanding traffic patterns.
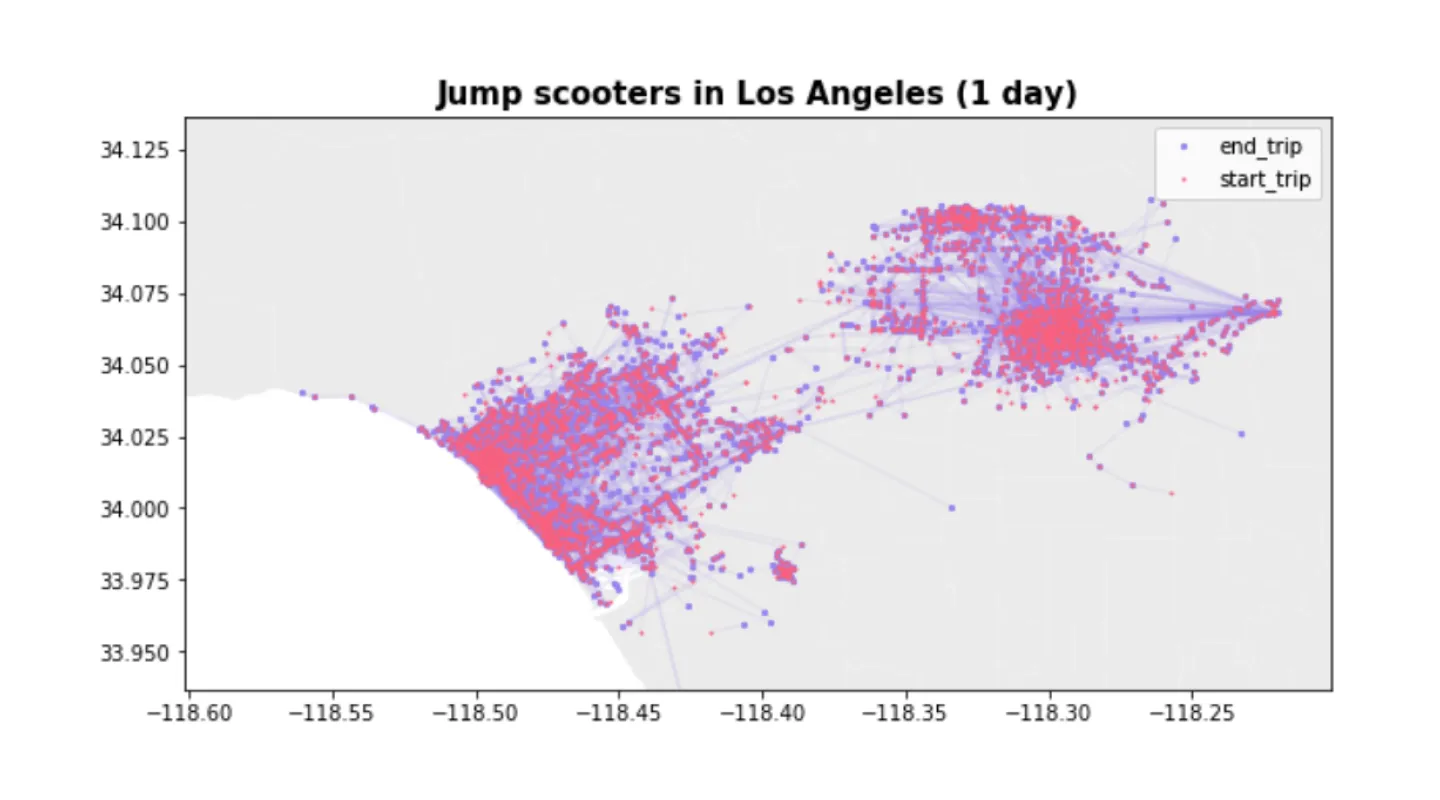
GBFS feeds are real-time, so you can only see data for the past minute or so. For this experiment, we collected an entire day of data. Let’s take a look at a full day’s ride-share data for Los Angeles to better understand it and see where we might be able to improve on some privacy guarantees. You can snag the raw version of the dataset we’re working with on our Github.
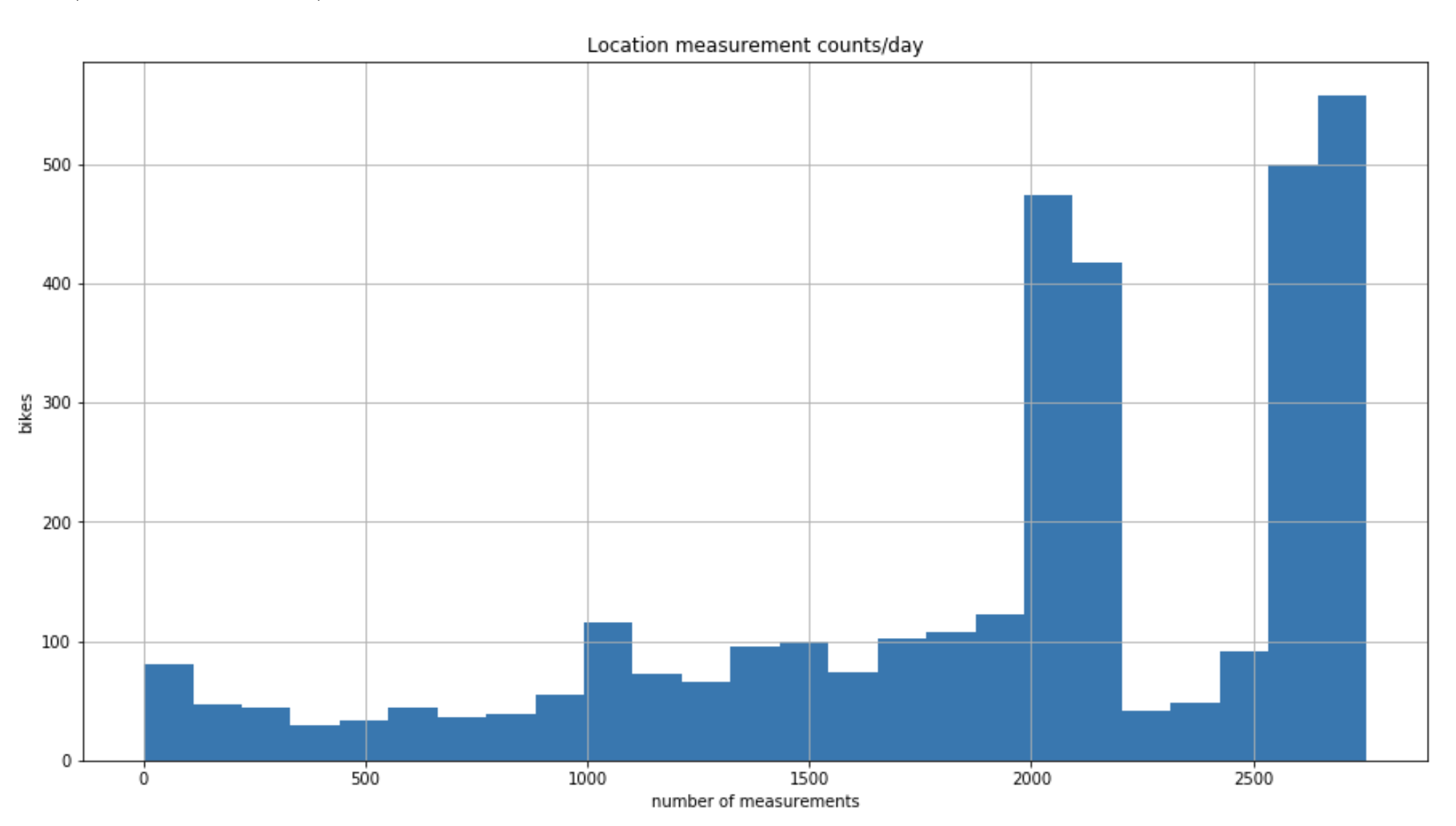
Initial observations are that there are over 6M location updates sent each day. Also, the GPS locations are quite precise (.000001 degrees = .111 meters!). Realistically, the GPS devices in scooters are most likely only accurate to a few meters.
The dataset contains 3,393 scooters in the LA area, each reporting its location on average 2,755 times per day (equates to reporting every~31 seconds at the 75th percentile).
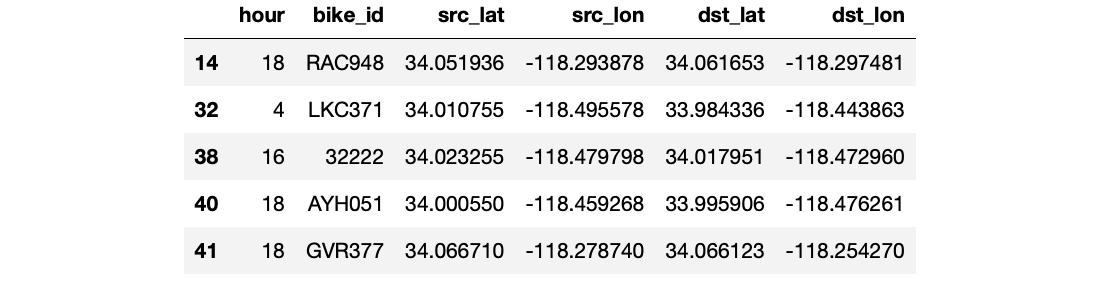
This is all great, but what’s really interesting is in learning about where scooters are going- data like this can help anywhere from civic planning, to thinking about where to put your new bar, restaurant, or even even where to advertise your business. To make this simple- we are working with only times that scooters reported location updates more than 100m from their previous position. We logged these updates over the course of one day, and you can download the dataset on our Github. Here’s the format:
The privacy challenge
While the ride share data is anonymized in a traditional sense and only tracking scooter locations over time, the combination of the precision of the location updates (.111m), the frequency of the updates (logging location by the start and end of each trip), and the ability to uniquely track scooters by name makes this data, in theory, open to re-identification attacks. In a re-identification attack, an attacker has some knowledge about an individual user, or a second dataset that can be joined with an anonymized dataset that can compromise individual privacy. Some widely known examples include researchers combining IMDB movie reviews and timestamps with the anonymized Netflix Challenge dataset to de-anonymize movie reviews.
Working with the scooter dataset in Los Angeles, the concern would be that if a bad actor (Alice) knew something about another individual’s location (let’s say Bob), such as where they worked, and that Bob often rode scooters home from work around 4pm, it’s theoretically possible that Alice could identify Bob leaving work on a scooter, and then track where he was traveling to.
Our goal for this post is to use machine learning to create an artificial, synthetic, dataset with almost all of the utility of the original dataset, but with enhancing the privacy for any individuals in the dataset.
If we can do this using synthetic data, Alice will no longer have the ability to identify Bob’s whereabouts by identifying a scooter’s time and location.
Build a generative model
We will begin by training a generative neural network on the real scooter data, and then use the neural network to create a synthetic dataset that, hopefully, contains many of the same statistical insights and applications as the original dataset, but with enhanced user privacy so that a bad actor, such as Alice (in the example above) would no longer have confidence that a particular record in the dataset is real.
There has been incredible progress in using Recurrent Neural Networks (RNN) and Generative Adversarial Networks (GAN) to generate realistic, but synthetic text (check out OpenAI’s GPT-2 to generate realistic text) and image data (check out Facebook’s Habitat to generate realistic environments). We will use a similar approach, using an RNN to learn and generate both a synthetic, and differentially private synthetic ride share datasets from real data.
First, we’ll load our entire CSV training corpus of scooter data as a text string. The next step is mapping strings to a numerical representation. Create two lookup tables: one mapping characters to numbers, and another for numbers to characters.
In the training dataset above, we discovered 66 different unique characters and mapped them to integer values. Here is an example of what the mapping looks like on the first line of input data:
Next, we set up the prediction task and training dataset. We are training our model to predict the most probable next character. The input to our RNN model will be a sequence of characters, and we train the model to predict the output — the following character at each time step.
In the example above, `split_input_target(“So hot right now”)` returns `(‘So hot right now’, ‘o hot right now.’)`.
Design the model
To build our model, we will use tf.keras.Sequential to define the next-char-prediction model, with atf.keras.layers.Embedding as the input layer to map numbers of each character to a vector with 256 dimensions. For classification, we’ll use two hidden tf.keras.layers.LSTM layers with 256 memory units, three tf.keras.layers.Dropout layers to help with generalization, and a tf.keras.layers.Dense layer for our output. The Dense layer acts as our output layer, using a softmax activation function to output a probability prediction for the next character for each of the 66 characters observed in our training set (between 0 and 1).
During training, our goal is to predict the next character in the dataset, while optimizing the log loss (cross_entropy). TensorFlow provides multiple choices for optimization, we’ll use the ADAM algorithm for its balance of performance and speed.
When generating a synthetic dataset, we are are not interested in the most accurate (classification accuracy) model of the training dataset. This would be a model that recreates the training set by perfectly predicting each character. Instead we are seeking a balance between generalization and overfitting that lets us create useful synthetic data containing the statistical insights of the original data, but that minimizes memorization of data and removes statistical outliers that impact user privacy.
Train the model
history = model.fit(dataset, epochs=15, callbacks [checkpoint_callback])
Generate synthetic records
Now, we’re ready to use our model to generate synthetic records!
- The code below uses a categorical distribution to calculate the most likely next character.
- The newly predicted character is appended to the existing text string, and on the next iteration fed back into the model.
- Experiment with the temperature setting to affect the randomness of the output of the model, by adjusting the thresholds for the selection of the next character from the categorical distribution. Sane values to try with are 0.1–1.0.
- To improve the model, try training on more data, or with increased epochs to 30.
Examining Synthetic Data
Even after training on a limited amount of input data, we can see that the RNN has learned the structure of the data and is generating realistic-looking data.

You can run through our sample code yourself here. For our privacy experiment, we’ll generate a synthetic dataset equal in size to the original training set, based on ~5800 scooter trips for 30 epochs. You should be able to generate useful data with a CPU if you’re patient- but I’d recommend a GPU- we’ll use an Nvidia Tesla T4.
Let’s plot our synthetic data vs original data to see if our model was able to generate useful data. Note that with limited input data, the output format is not perfect- expect to do some light-weight filtering for missing field values/etc!
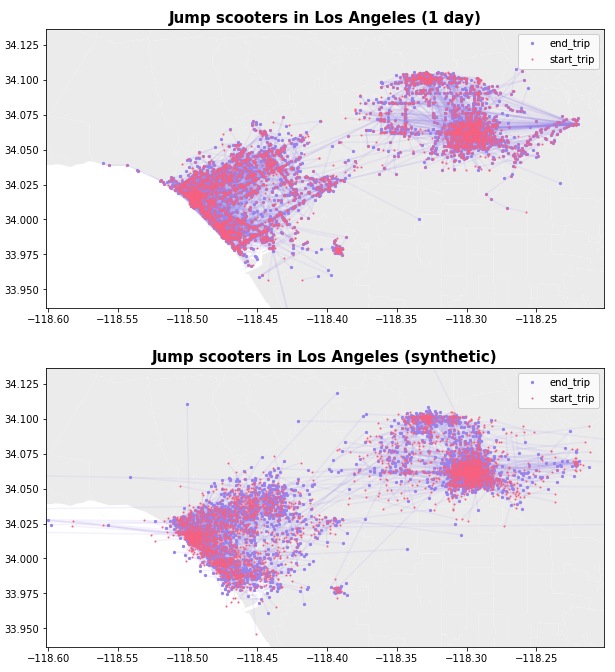
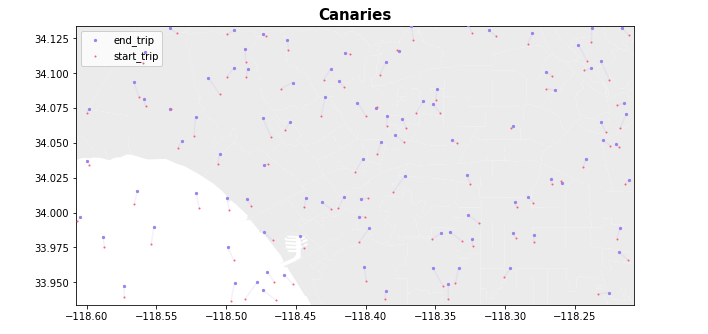
Our 5,800 ride dataset is gathered from Uber ride shares all over the United States, and we are diving into the Los Angeles region to visualize some of the micro patterns that emerge in our model that would not be apparent zoomed out at the country level. At first glance, our synthetically generated dataset looks pretty good. There are a few scooters in the ocean, and a few scooters up North, but we have the benefits of what appears to be a statistically similar dataset (we’ll dive into this in the Part 2), and as the data is effectively generated by our ML model, we hope to have have greatly reduced the chance that a single ride will be memorized by our model, and that a bad actor will be able to use it to compromise individual user privacy.
Why Differential Privacy
What if we were releasing a dataset to the world, and wanted to provide mathematical guarantees that no individual trip in our training set (in our example earlier, Bob taking the scooter home from work) would be memorized by our model, even at the expense of some accuracy?
Differential privacy is also promising for maintaining machine learning models in an environment with GDPR, CCPA, or HIPAA. Many companies building machine learning models from customer data face the challenge that when a customer wishes to have their individual data deleted, that any models based on their individual data need to be recomputed as well. Differentially private learning helps prove that one individual’s data will not be memorized by a machine learning model, and thus you may not to retrain your models. But, this privacy comes at the expense of a hit to accuracy. Below, we can see that differential privacy becomes usable at a much smaller and more accessible scale than you might think.
Applying Differential Privacy to our model
The TensorFlow team has taken on a lot of the heavy lifting of implementing and released TensorFlow Privacy, an extension to TensorFlow that allows differentially private learning.
Let’s build support for differentially private learning into our character-RNN generative model, and see if we can still use it to create realistic and usable data, while maintaining an acceptable privacy-loss (epsilon) value.
In the code above, we make changes to the our existing model- specifically gradient clipping and noising in the training optimizer. First, we need to limit how much each individual training point sampled in a mini-batch can can possibly impact model parameters, and the resulting gradient computation. Second, we need to randomize the algorithm’s behavior to make it statistically impossible to know whether or not a particular point was included in the training set. We achieve this through sampling random noise and adding it to the clipped gradients. This is where TensorFlow Privacy kicks in: it provides code that wraps an existing TF optimizer that performs both of these steps needed to obtain differential privacy.
Next, we need to tune our hyper parameter selections to support private learning with a minimal epsilon value. Intuitively, we’ll want to lower the rnn_unit size to minimize complexity of our network. Tuning the other parameters to get usable results from our differentially private algorithm is not so easy. Fortunately, in the “The Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks”, by Nicholas Carlini, Chang Liu, Úlfar Erlingsson, Jernej Kos, Dawn Song, the researchers point out some useful parameters for configuring differentially private learning. Most notably, replacing the plain Differentially Private SGD optimizer with a DP RMSProp version provided significantly higher accuracy than the default implementation. We saw gains here as well. Using the RNN and differential privacy learning settings below, we were able to achieve an epsilon of 0.666 and delta of 6.53e-07 with a 0.96 categorical cross-entropy loss on 27,000 bike share trips.
Visualizing the Synthetic Datasets
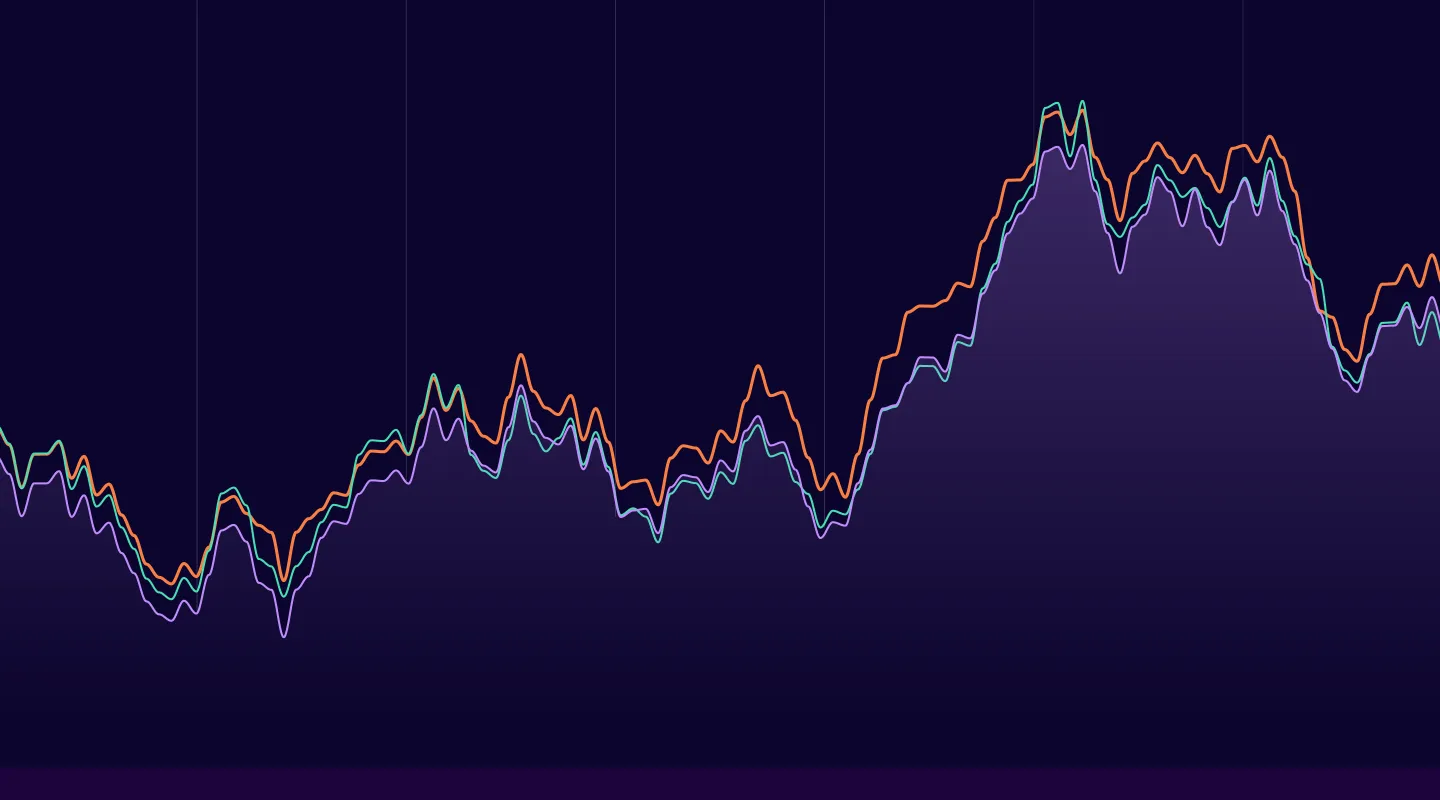
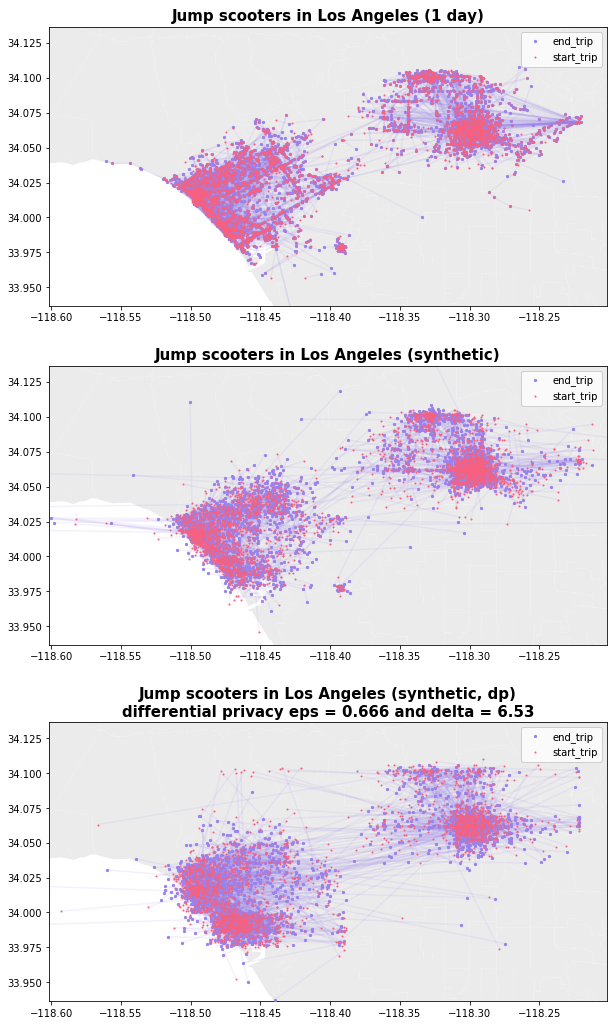
Phew! Now for the moment we’ve been waiting for, let’s graph the original ride share data, synthetically generated (non-private) version, and finally the differentially private synthetic datasets and see how the DP model performs.
Quantifying the Privacy of Synthetic Data
To quantify the privacy of our newly generated synthetic dataset, there is one question that immediately comes to mind
Did our model memorize any of the input training data, and play it back during synthetic dataset generation?
To test this, we’ll take two approaches. First, we will see if any of the training data was memorized and replayed exactly by our synthetic model (e.g. duplicate records). Second, we will insert “canaries”, which are fake, but less-than-random scooter rides into the training dataset. Finally, we will train models using a variety of settings, and generate synthetic datasets for each configuration. We can then search for the existence of any training data (which may have repetitions and overlaps in locations resulting in memorization), and canaries (more randomized, but still realistic) in our synthetic datasets.
To make the canaries, we generated a bounding box around the Los Angeles area, interpolated a 30x30 grid, inserted random noise to both the source and destinations to keep our model from memorizing any similarities, and selected 100 data points at random for the canaries (canaries account for 1.72% of overall training dataset).
Below are the results of three models trained with different settings, including “C3”, which utilizes differentially private learning. C2 uses 1024 LSTM units and 100 epochs to intentionally overfit the data.
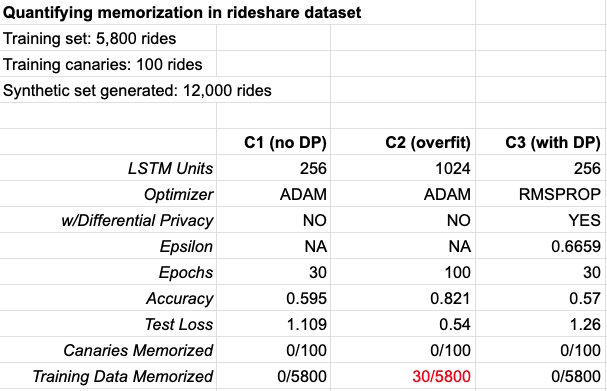
The 12,000 record synthetic dataset generated by our C1 and C3 models do not contain a single record that’s identical to the training or canary data, indicating that the model selection parameters are performing well towards of goal of capturing statistical insights, but not memorizing data. While C2 performs very well (82% accuracy) and did not memorize any of our artificial canaries, it did perfectly replay 30 out of 5800 training records in the 12,000 synthetic records that we generated. Configuration C3 utilizes differentially private learning, with a DP epsilon of 0.66 over 30 epochs, with mathematical guarantees around privacy with only a 3% drop in accuracy vs C1.
Thoughts
The DP dataset is clearly still generating statistically relevant and useful locations (even if there are now some scooters in the ocean), this is a dataset that can be used with nearly the same accuracy and shared freely with guarantees of protecting individual user privacy, and that’s pretty cool.
Check out the code at https://github.com/gretelai.