Practical Privacy with Synthetic Data

TLDR;
In this post, we will implement a practical attack on synthetic data models that was described in the Secret Sharer: Evaluating and Testing Unintended Memorization in Neural Networks by Nicholas Carlini et. al. We will use this attack to see how synthetic data models with various neural network and differential privacy parameter settings actually work at protecting sensitive data and secrets in datasets.
Oh, and we found some pretty surprising results…
Background
Open datasets and machine learning models are incredibly valuable for democratizing knowledge, and allowing developers and data scientists to experiment with and use data in new ways. Whether the datasets contain location data, imagery (such as camera video), or even movie reviews, the underlying data used to create these datasets often contains and is based on individual data.
Synthetic data models are a promising technique for generating artificial datasets that contain the same insights and distributions as the original data, without containing any real user data. Potential applications include allowing medical researchers to learn about a rare disease without learning about the patients, or training machine learning models on private data without exposing potentially sensitive information.
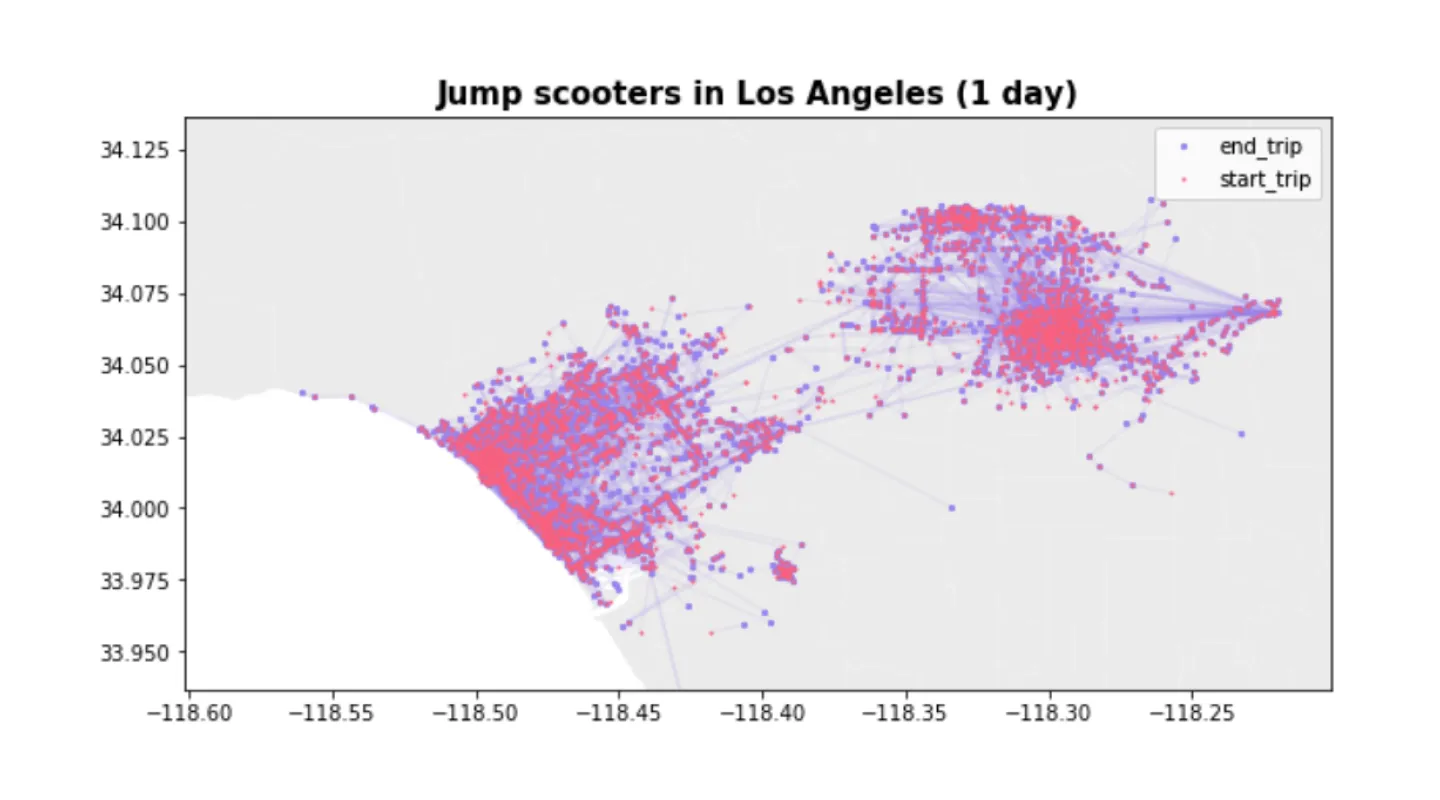
The dataset
Traditionally, successful applications of differential privacy have been shown with massive datasets containing highly homogeneous data. For example, the US Census data, or emoji prediction for Apple devices. These datasets have 100s of millions of rows, and lower dimensionality, making them ideal candidates for privacy preserving techniques like differential privacy. For this example, we will work with a much smaller dataset that is based on a public feed of e-bike ride share data. What makes this dataset interesting for our dataset? It contains sensitive location data, which has long been considered a challenge to properly anonymize. Secondly- we’re working with a dataset that’s under 30,000 rows of input data and more representative of the typical datasets data scientists work with each day.
Let’s see if we can build a synthetic dataset with the same insights as the raw data, but without using real trips or locations. For this example, we logged a public ride-share feed over the course of one day in the Los Angeles area, and you can download the dataset on our Github. Here’s the format:

The attack
We will implement a practical attack on Gretel.ai’s data model (this will work on any generative language model) by inserting canary values at various frequencies randomly into the model’s training data. We can then use that data to generate models with various neural network and privacy settings, and measure each model’s propensity to memorize and replay canary values.
How will these results differ from the guarantees that differential privacy provides? Well, we cannot mathematically claim that a model is private if these attacks pass. E.g. It is possible that a model has memorized some un-intended information (canary values) that simply have not been replayed by the model yet. That said, knowing that you can insert a canary value between 10 and 100 times in a dataset and not see it repeated does provide practical checks on your model, _and_ that your expectations around privacy guarantees appear to be holding.
Let’s start by generating random secrets to insert into the training data.
Next, sample the training set and add new records containing canary values.
We can use a simple helper to search for the existence of the secret strings in generated data. Let’s see how many values of each secret we will be inserting into the training data.
Run the experiments
We are ready to run our experiments by training synthetic data models on our new training set containing various quantities of canary values. In the experiments below, we trained synthetic data models with 10 different configurations and with canaries inserted between 18 and 138 times into the training data. We then counted the number of secrets that were replayed by the model during generation.
To try this yourself, check out our example notebook.
Examining the results

As we can see, the standard synthetic data configurations without differential privacy in Experiments 0, 1, and 2 provided reasonable protections against rare data and secrets being learned, with the secret needing to be present over 18 times in the training data to be memorized and replayed by the model.
Differential privacy worked quite well at preventing memorization of secrets across all tested configurations. Experiment 9 used a relatively high noise multiplier (0.1) and aggressive gradient clipping (1.5) which resulted in zero canaries being replayed in the generated data, but with a substantial decrease to model accuracy.
To our surprise, simply using gradient clipping in Experiment 6 and a minimal level of noise into the optimizer prevented any replay of our canary values- (even secrets repeated 138 times in the data!) with only a small loss in model accuracy.
Next steps
For many use cases with data, such as training ML models- we are balancing the privacy guarantees of data with utility and accuracy. Try experimenting on your own data with different parameter configurations to find the right balance.
Have your own use case to chat about? Send us an email at hi@gretel.ai or join our community Slack at https://gretel.ai/slackinvite.