How to safely work with another company's data

Machine learning drives technologies with wide-ranging impact in the contemporary world and data drives machine learning. Access to data is essential, but complicated given security and privacy. This is especially true in consulting where access to any data requires interfacing with the customer and their systems, and satisfying their security and privacy requirements.
Even with top-of-the-line data security measures in place, clients are regularly concerned that without taking proper privacy preserving precautions, you may accidentally open them up to various attacks that can compromise their sensitive data. One precaution is for clients to provide synthetic data, rather than real data, for consultants to use and analyze. Consultants can even propose this as an option for their clients who are particularly concerned about security and privacy.
In this blog we describe a hypothetical attack on a customer's private data and showcase how a consultant might use synthetic data to eliminate this risk while still fulfilling the client’s requirements for predictive machine learning models.
Scenario
In our scenario, we’re a consultant working with a large grocery store to build a predictive model of customer purchasing behavior. The predictive model will be a classification algorithm that takes information about a customer’s shopping cart and predicts how likely they are to purchase a frozen pizza. The grocery store wants to target select customers, sending them a coupon to encourage them to buy the pizza and increase sales.

The dataset’s columns have items a customer plans to purchase, and each value is the number of such items in a customer’s cart. In this scenario, we’re tasked to use this data to build a predictive model for the grocery store.
It’s important to note that in addition to the cart information, the data includes three columns that may appear innocuous but are potentially a broken stone in our privacy pyramid.
Linkage Attack
The columns order_day_of_week, order_hour_of_day, and days_since_prior_order appear like simple informative features that can help us predict a shopper’s behavior. However, if an attacker with access to the data combined that information with an external dataset of location data they could associate personal information with potentially sensitive shopping information.

This attack is called a linkage attack, and involves an attacker linking information from one dataset to another while using that link to discover personal information from one or both datasets.
The Synthetic Data Defense
Fortunately, privacy preserving synthetic data allows us to use this sensitive information for building the predictive model while significantly reducing the risk of a linkage attack.
This dataset is sparse (many empty, missing, or zero values) with a large number of categorical columns. For this dataset, we will use the CTGAN model provided through Gretel’s APIs to create an artificial, synthetic version of the real world data. In general, CTGAN is a good choice when the data is high dimensional, meaning it contains many columns. When combined with Gretel’s privacy filters, CTGAN can provide strong protections against data linkage attacks, even when working with high dimensional datasets. Note that other models, like Gretel’s LSTM, also provide privacy-preserving properties — including support for differential privacy — and could be used at the consultant’s discretion. (Update: As of May 8, 2023, Gretel has deprecated DP support in Gretel LSTM in favor of the new Gretel Tabular DP model.)
The classification pipeline follows a standard machine learning process, with an additional data synthetics step.
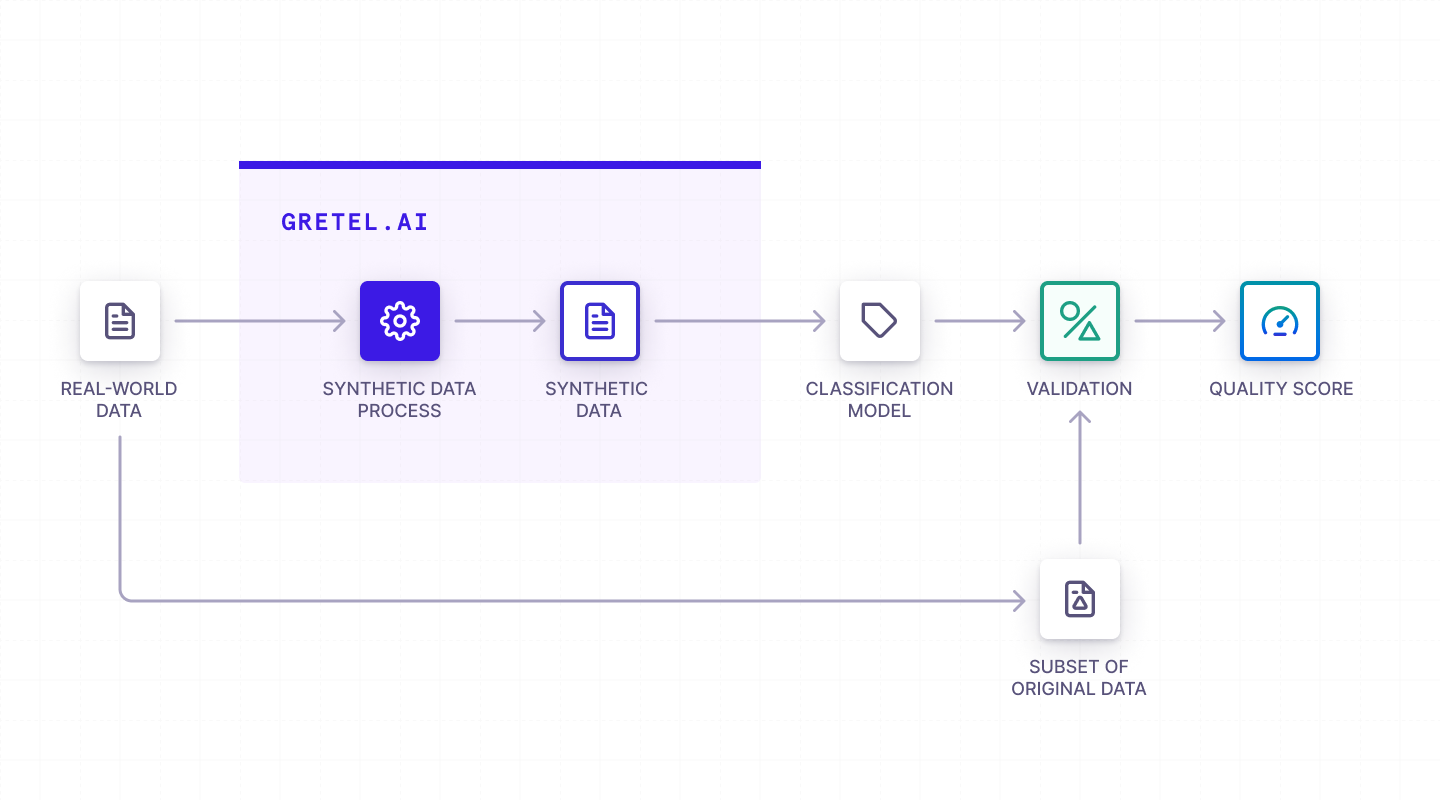
CTGAN Model
The original paper [1907.00503] Modeling Tabular data using Conditional GAN introduces the Conditional Tabular Generative Adversarial Network, which enables synthetic data generation by GANs for tabular data. As mentioned before, this particular model is well suited for sparse datasets with many zeros, missing, or empty values, and a larger number of columns.
We train it through the Gretel API and synthesize 5,000 records with the entire process taking less than 15 minutes. Using the SQS our synthetic data has an Excellent rating, which means it's ready to be used! Sharing and using synthetic data has much less privacy risk than the real data, but the synthetic data has many of the same important statistical qualities, patterns, and relationships necessary for downstream machine learning. Additionally, we can easily generate more synthetic data for our downstream classifier, which can increase the classifier’s performance on pizza prediction.

Downstream Machine Learning
We perform the usual classifier training tasks, only this time using synthetic data for training rather than real data. We do a 10-fold cross validation with a logistic regression classifier on the synthetic data to find a hyperparameter configuration that works well. After fitting the model on the synthetic data the client validates the model on real data. The resulting model performs well, with an F1 score of 0.9249.
One might be curious if better accuracy could be achieved using the real data, and by how much. We find that a classifier trained on the synthetic data achieves performance on the real data very comparable to a classifier trained directly on the real data, with an F1 score of 0.9206. So, with no discernible accuracy change, we nearly eliminated the possibility of a linkage attack because no record in the synthetic data is based on an individual human’s data.
Conclusion
In consulting, there are many things to track. Putting a client’s mind at ease about the safekeeping of sensitive data is an important part of the process. By using synthetic data, consultants can sidestep the data access problem while creating high-quality machine learning models for their clients. In this scenario, we outlined a scenario where synthetic data can protect sensitive customer data while still allowing consultants to deliver value to their clients.
If you want to learn more about CTGAN or our synthetic data generation systems, feel free to reach out at hi@gretel.ai or join and share your ideas in our Slack community. To get started right away, sign into the Gretel Console and create your first synthetic dataset in minutes.


