Generate Synthetic Databases with Gretel Relational

Introduction
Relational databases are a cornerstone of enterprise data management. Such databases often contain hundreds of interrelated tables, and form the backbone for several use cases within an organization. While democratizing this data across teams comes with major productivity benefits, access to these databases often remains restricted due to privacy and security concerns, constraining innovation, or forcing teams to rely on proxy datasets that may not offer the same quality of insights. For over 23,000 developers, generating synthetic data with Gretel has become a preferred solution to combat this data bottleneck by creating synthetic versions of single tables that preserve the statistical properties of the original data while providing advanced privacy guarantees. Today, we’re excited to announce the general availability of Gretel Relational, which leverages our library of generative AI models to synthesize large multi-table databases while maintaining referential integrity and statistical accuracy.
Gretel Relational offers the high-quality Gretel Synthetics models you know and love, now for multi-table and relational databases. With over 30 available connectors, you can synthesize data from and write back to popular databases and data warehouses like Oracle, MySQL, MariaDB, Microsoft SQL Server, Snowflake, SQLite, PostgreSQL, and more.
In this blog, we'll walk through a practical example of generating a telecommunications database using Gretel Relational. You can follow along with our Gretel Relational Synthetics demo notebook located here or here:
Walkthrough
Our database
In this example, we have a telecommunications company who wants to anonymize their database due to privacy and security concerns. The database contains sensitive information including customer names, social security numbers, addresses, SIM numbers, and transaction history. Due to privacy and security concerns, the data can't be shared outside a limited group of authorized employees. Access to this information is crucial, but currently restricted, for the team tasked with analyzing the data to identify and predict trends, such as the number of accounts by geographic location, or the likelihood a client will have a late payment. For this data analysis use case, optimizing for statistical accuracy and maintaining the size of the database are the primary objectives. By synthesizing this database, the data can be shared safely, while also maintaining its referential integrity and accuracy.
The relational database we’ll be using is a mock telecommunications database shown below. This contains five tables that store information about product data, customer information, and transaction history for phone plans. The `client` table represents the person associated with each phone plan. It has two child tables: `location`, which contains the address of each client, and `account`, which represents all the devices on a client’s plan. Additionally, an `invoice` table is maintained to track each bill associated with an account, and the `payment` table tracks the transactions related to each invoice.
In the figure below, the lines between tables represent primary-foreign key relationships, which are used in relational databases to define many-to-one relationships. To ensure relationships within and across tables are maintained, a table with a foreign key that references a primary key in another table should be able to be joined with that other table. Below we'll demonstrate that referential integrity exists both before and after the data is synthesized. We'll also assess the statistical accuracy and privacy of the synthesized data.

Define source data via a database connector
To begin, we specify the real-world data we’ll be synthesizing. There are two ways to define relational data - automatically via a database connector or manually with individual table files. Gretel Relational supports connectors for any database supported by SQLAlchemy, and has first-class helper functions for PostgreSQL, SQLite, MySQL, MariaDB, Snowflake, and more. For more information about connecting to your own database, check out our docs. In this notebook we'll use a SQLite connector to automatically extract the data and schema from the telecom database. The extracted relational data contains the table data, the primary and foreign keys, and their relationships.
Alternatively, you can define the input relational data from individual table files. In this case, the table names, keys, and their relationships are defined manually.
Examine the input data
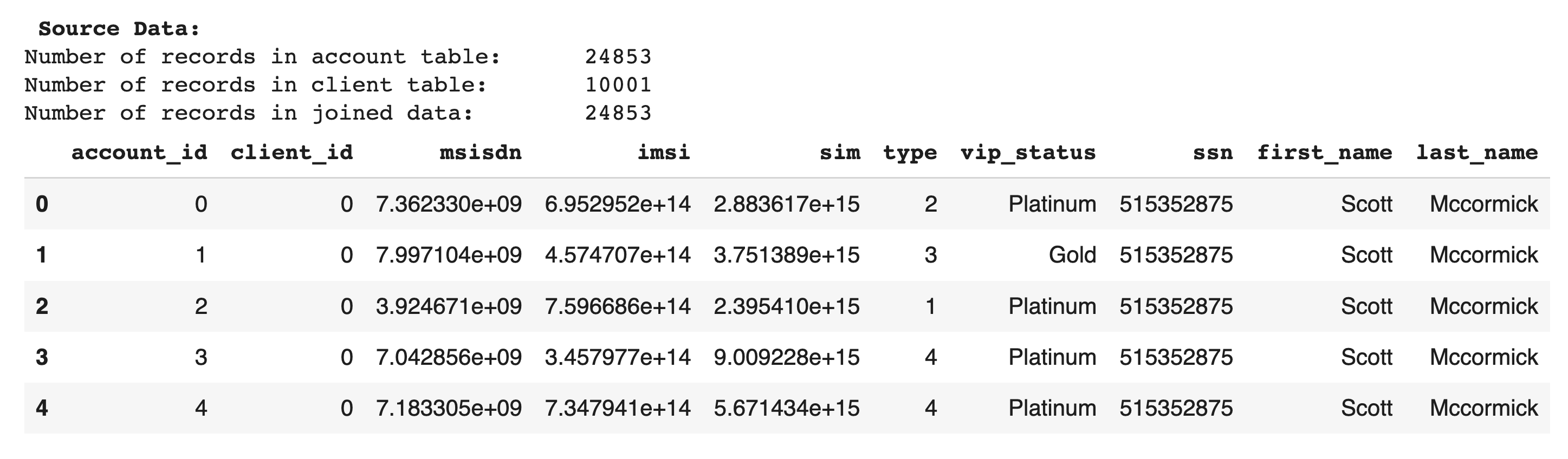
Now, we’ll join related tables `account` and `client` using the key `client_id`. Let’s preview the joined data to confirm referential integrity of the source data. In the output below, note that every record in the child table `account` matches a distinct record in the parent table `client`. Therefore, the number of records in the joined data matches the number of records in the child table. This confirms the referential integrity of the source data. After we synthesize the database, we'll use the same method to confirm that this integrity has been maintained.
Synthesize Database
Create the relational model and project
Next, we set up our relational model and create a project using the `MultiTable` instance. The `MultiTable` class is the interface to working with relational data. It will be used later to control model training and data generation, and to evaluate the quality of the synthetic database. For Gretel Relational Synthetics, there are three model options - Gretel Amplify, Gretel ACTGAN, and Gretel LSTM. In this notebook, we are using Gretel Amplify. The cell below sets up the relational model and creates a project as specified by `project_display_name`. This project will house all models and artifacts associated with the database synthesis. During this step, you'll be prompted to input your API key, which can be found in the Gretel Console.
Synthesize a database
Now it's time to train and generate the synthetic database.
The code shown above trains an Amplify model for each table in the database. The logs refresh periodically to provide status updates.

After about three minutes, training is complete and we can begin generating the synthetic database. For our use case today, we want to generate a synthetic database that replicates the original, so we will generate the same amount of data for all tables. Alternatively, you can choose to subset your existing database or generate even more data by adjusting the `record_size_ratio` parameter. Additionally, you can choose to exclude specific tables from synthesis with the `preserve_tables` parameter.
As with training, logs refresh throughout the generation process to provide status updates. Because it’s possible to generate data many times from the same relational model, each synthetic generation run has an associated generation ID, which is always logged at the beginning of the generation. This ID can be helpful for identifying artifacts — synthetic tables, reports, etc. — after generation. By default, the ID is `synthetics_{timestamp}`, but you can set a custom ID by including an `identifier=”my-custom-id”` parameter.
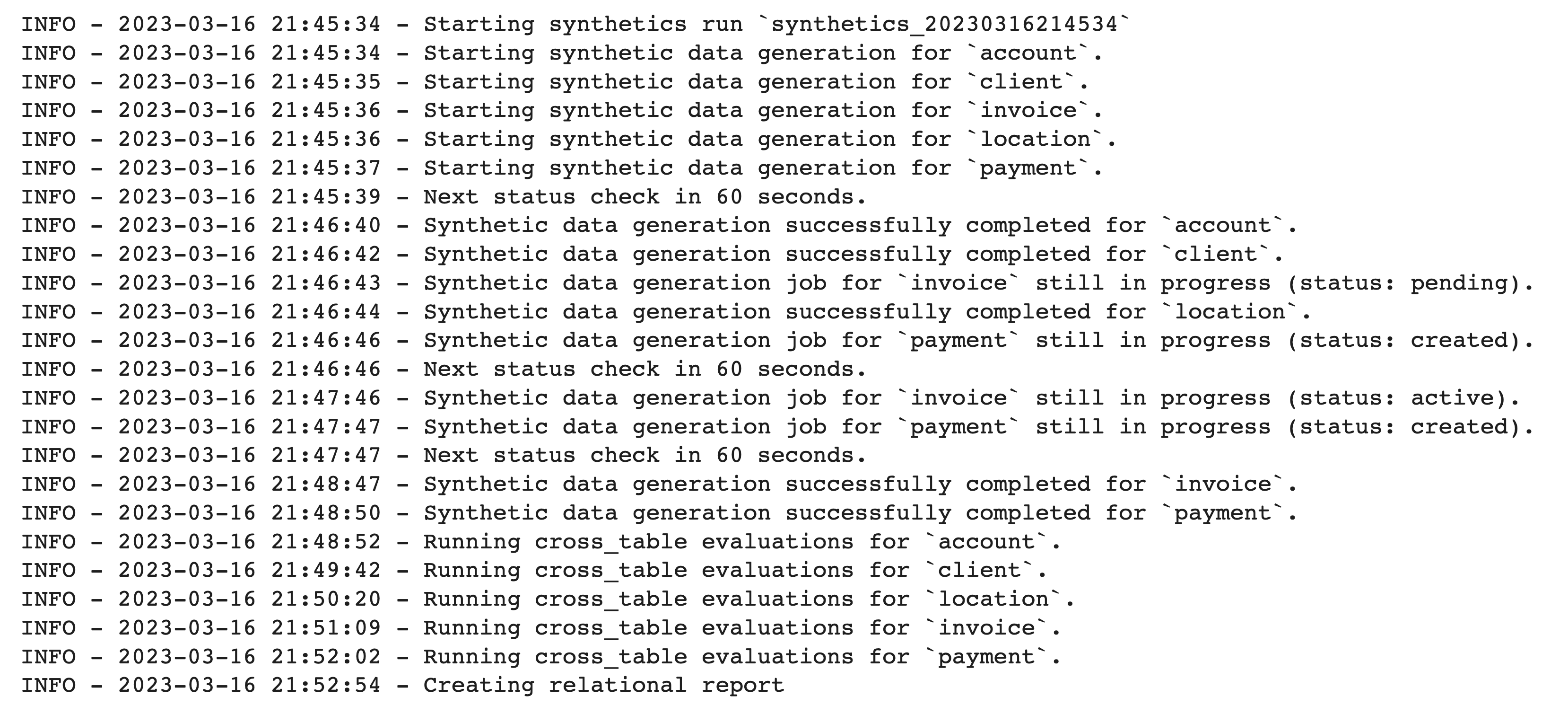
After only seven minutes, we’ve generated a synthetic version of the entire database with five tables and over 231,000 records.
View Results
Preview Table Data
Now, let’s take a look at our results. First, we’ll compare the original and synthetic data from a single table in the database.
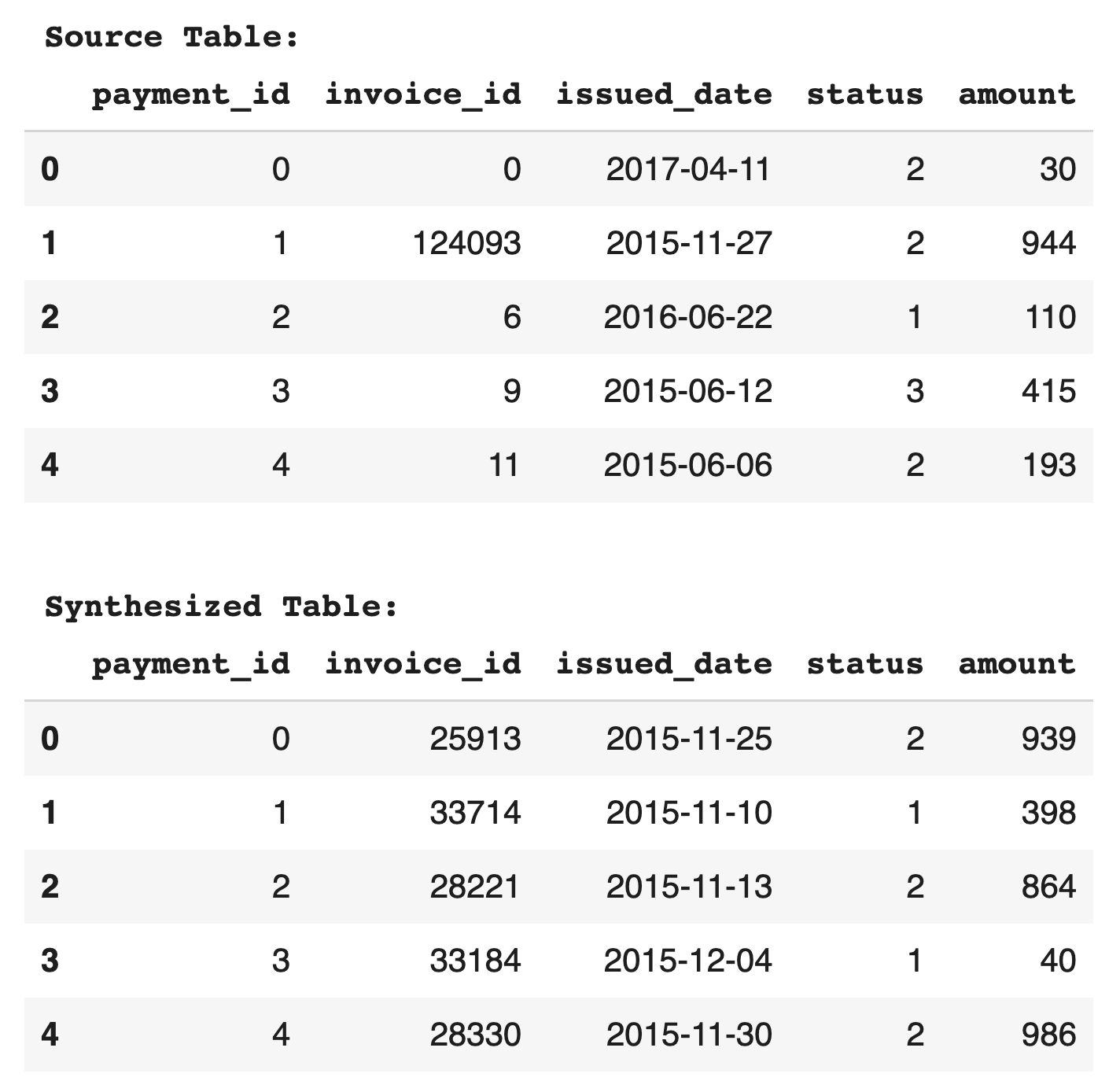
Looking at the first five records of the `payment` table, we see that the synthesized table fields match the data types and provide logical values for their corresponding original fields. Each `payment_id` maps to a unique `invoice_id`, as expected. Examining the entire dataset, both the source and synthesized tables have `issued_date` ranges between December 2013 and May 2017, and `amount` ranges between $1 and $1,000. For a more detailed examination of the quality of the data, we will look at the Gretel Relational Report below.
Confirm Referential Integrity
Now, to test referential integrity, we'll show the same join on the synthetic `account` and `client` tables as we did for the source data. If referential integrity has been maintained, the child table and the joined data should have the same number of rows.
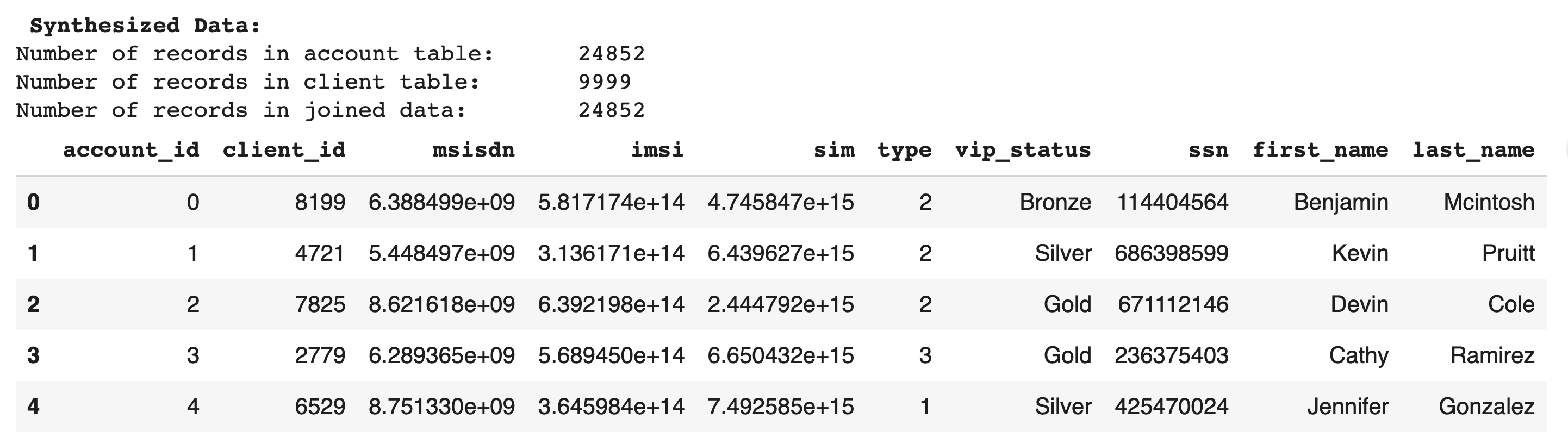
As with the original data, every record in the synthesized child table, `account`, matches a distinct record in its synthesized parent table, `client`. The number of records in the child table and in the joined data match, confirming that referential integrity has been maintained. Additionally, looking at the values of the fields confirms that logical data has been generated. The name fields contain names, `ssn` contains nine digit numbers, etc.
Gretel Relational Report
During each database generation, a Gretel Relational Report is created. Similar to the single-table Gretel Synthetic Report, the relational report helps you assess the accuracy and privacy of your synthetic database as a whole and of the individual tables.
To view the report in the notebook, we can run the cell below.
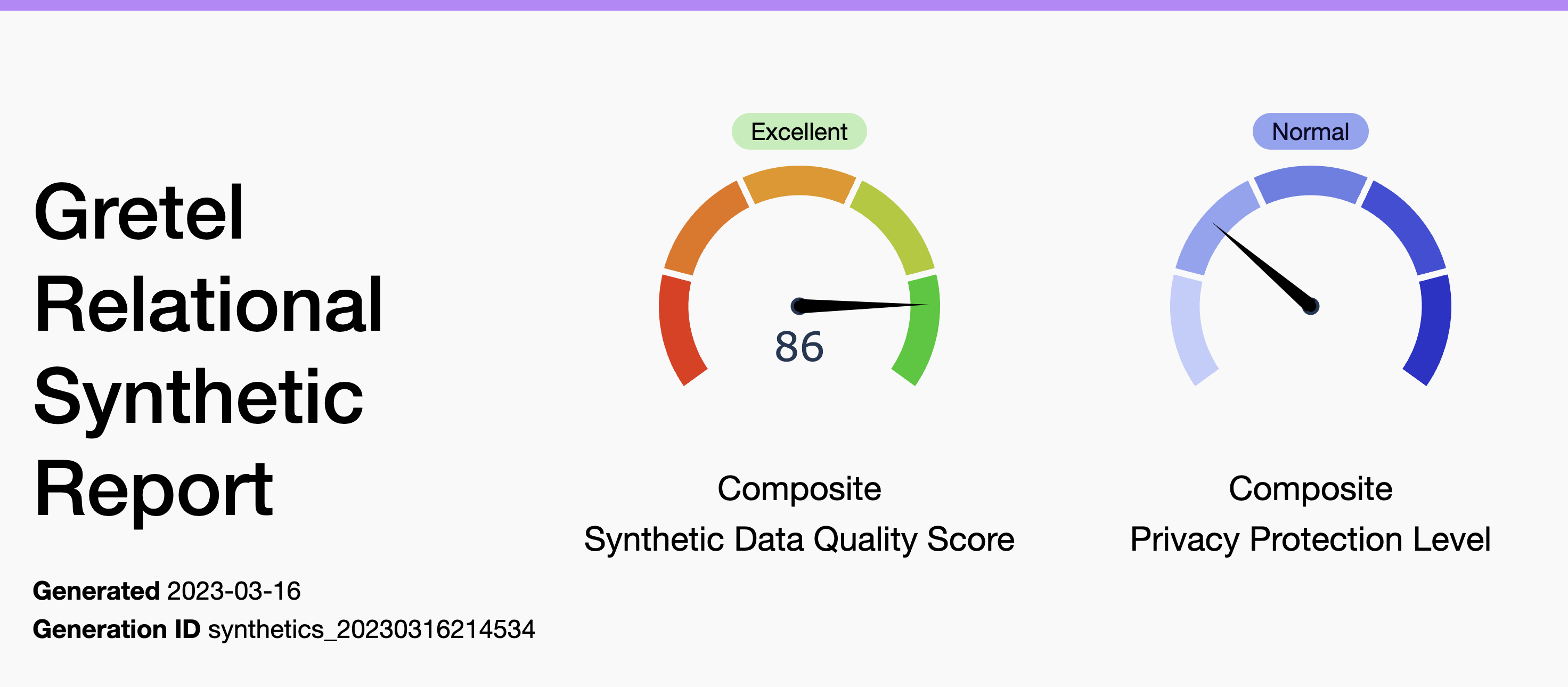
At the top of the report, the synthetic data quality score (SQS) and privacy protection level (PPL) for the database are shown. These are composite scores that represent the accuracy and privacy of the whole database. Later in the report, scores are also provided for each table. The quality score is an estimate of how well the generated synthetic data maintains the same statistical properties as the original dataset. In this sense, the Synthetic Data Quality Score can be viewed as a utility score or a confidence score as to whether scientific conclusions drawn from the synthetic dataset would be the same if one were to have used the original dataset instead.
Our synthesized telecommunications database has an ‘Excellent’ Composite SQS of 86 and ‘Normal’ PPL. An ‘Excellent` SQS, the highest grade, means that the synthetic data quality is ideal for our statistical analysis use case. The ‘Normal’ PPL means that the data is safe to be shared internally with the data analysis team.
The report includes a visual of the key relationships between tables in the database, as shown below. When the cursor is hovered over a key, its related keys and tables highlight.

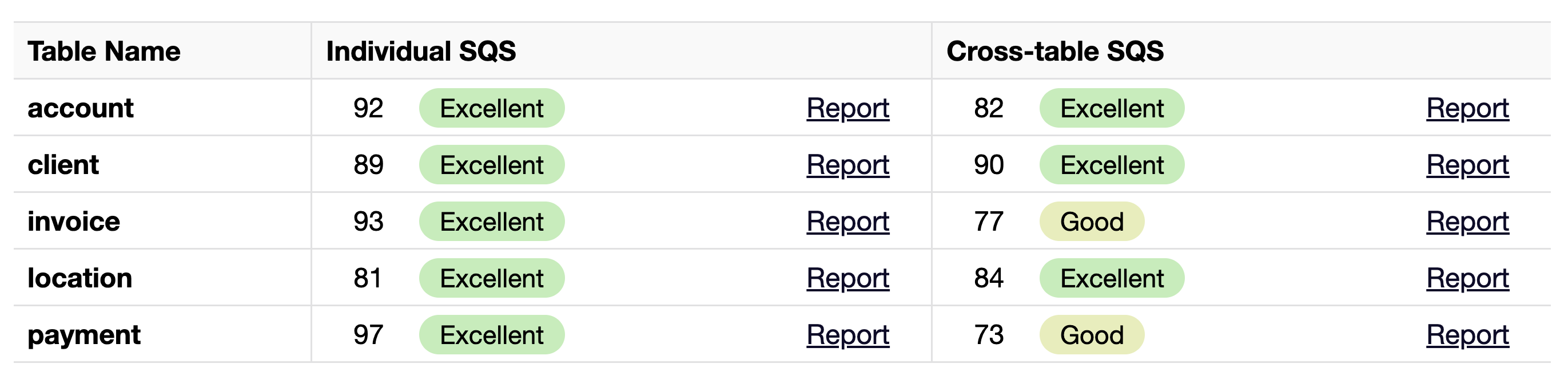
For each table, individual and cross-table Gretel Relational Reports are generated, which include additional quality scores. The individual report evaluates the statistical accuracy of the individual synthetic table compared to the real world table it is based on. This provides insight into the quality of the stand-alone synthetic table. The cross-table report evaluates the synthetic data of the table and all its ancestor tables. This provides insight into the accuracy of the table in the context of the database as a whole.
The table below displays the data quality scores, grades, and links to each respective report. With eight ‘Excellent’ and two ‘Good’ scores, we can feel confident that our synthetic database has the accuracy level recommended for our data analysis use case.
Output Files
All of the Relational Synthetics output files can be found in your local working directory. Additionally, if you’d like to access them via the Gretel Console, you can use the following cell to quickly obtain the URL:
Write synthetic results to a database via connector
Finally and optionally, we can write our synthetic results to a database via a connector. This can be the same database used for the source data or a new database. Here, we write to a new SQLite database `synthetic_telecom.db`. In this example, we add the prefix “synth_” to each table name.
With over 30 supported databases, check out our docs to learn more about writing to your own database.
Conclusion
Gretel Relational makes it easier than ever to connect to and synthesize databases using Gretel’s industry-leading generative AI models. We’ve demonstrated that referential integrity and statistical accuracy are maintained when generating a synthetic database with Gretel Relational. With the ability to quickly evaluate the quality and privacy of the synthesized database, you can be confident that your data is accurate and secure.
How will you use Relational Synthetics? Let us know! Feel free to reach out at hi@gretel.ai or join our Discord Community and share your thoughts.


