Contact Tracing: Deep Dive & Simulation
There’s been a lot of scrutiny, concern, and analysis of the Contact Tracing proposal from the joint Apple + Google effort to provide privacy preserving capabilities that inform people when they have been in close proximity to a COVID-19 infected person. I decided to examine this a little further to see exactly what was being proposed, how it would be implemented, and what privacy concerns there are.
I implemented the cryptographic portion of the specification in Python and created a rudimentary “Life” simulator that shows what results can be expected. The code is available on GitHub.
The big takeaway is Apple and Google’s specification substantially lowers privacy risk for contact tracing by not collecting existing data, but by generating new custom data specific to the use case. This privacy preservation happens at the lowest possible level. The handset can compute as much data as possible but share as little as possible in order to provide effective contact tracing while preserving user privacy.
Summary
- This is not location tracking. There is no GPS collection. Handsets exchange secure unique bits of data using Low Energy Bluetooth connections which are only possible when the handsets are near each other.
- This would be an opt-in program, to include the voluntary reporting of a positive COVID-19 test.
- As written, no specific personal or handset information needs to ever leave the device. Only the cryptographically secure keys or signatures that were created for and only for this use case need to be sent externally for effective results.
- The privacy focus is about ensuring the application and aggregator of the self-identifying subject data cannot identify who you are or who you have interacted with.
- The biggest risk to privacy will be how application developers implement the extraction and storage of Daily Trace Keys and what additional pieces of information they might request (or take) that are not within the scope of the initial specification.
Crypto Components
The core of this specification is creating a 3-tier system of secure identifiers / keys that can be selectively exchanged.
The first component is the handset Tracing Key. The Tracing Key is a unique 32-byte base encryption key that will never leave the device. Ever.
Second is the Daily Trace Key (DTK). This is a derivative encryption key that is created every 24 hours using a HMAC Key Derivation Function (HKDF). This key:
- Will never leave the handset if the the handset owner never reports a positive infection.
- Will leave the handset if and only if the owner reports a positive infection.
- If a positive infection is reported, the last N (14 days) DTKs will be transmitted and only transmitted to a remote system (presumably maintained by the application developer or agency). This is done so the remote system can distribute these DTKs to all other handsets to determine potential risky contacts.
Finally, there is the Rotating Proximity Indicator (RPI). This essentially is a 16-byte digital signature that is derived from a particular DTK. For a single DTK, there can be up to 144 unique RPIs. We use a HMAC to compute this and part of the message component to the HMAC is the nearest 10-minute interval for that day.
- 00:00–00:10 = interval 0
- 00:10–00:20 = interval 1
- …
- 23:50–24:00 = interval 143
We concatenate the interval number to the string “CT-RPI” to create the message we are hashing.
So we compute the first RPI of the day as HMAC(dtk, “CT-RPI0”, sha256) and the last RPI of the day as HMAC(dtk, “CT-RPI143”, sha256).
Technically, the device only computes a new RPI when the Bluetooth MAC address changes but the specification allows for every 10 minutes if needed. MAC address rotation is usually between 10 and 20 minutes.
Proximity Exchange
So, at any given point in time. A single handset will have:
- Exactly one Tracing Key
- Exactly one “active” Daily Tracing Key
- A historical list of previously used Daily Tracing Keys
- Exactly one “active” Rotating Proximity Indicator
Because of the chain of custody from the base Tracing Key we are almost sure there will be no collisions across these varying components.
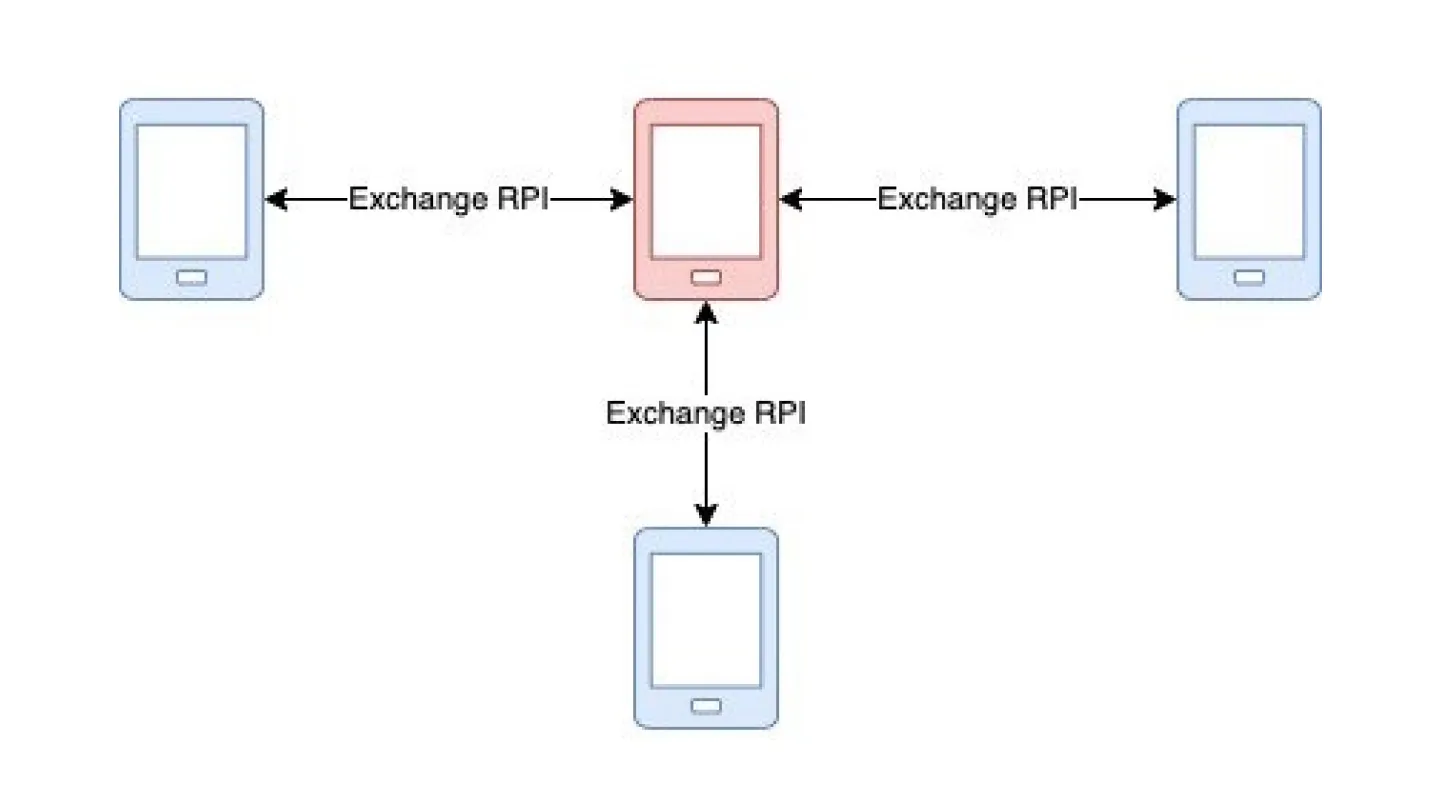
When 2 handsets come within close proximity to each other (which is detected by one handset sensing another bluetooth device near by), each handset will send the other handset its current RPI.
So if handsets A and B come within a proximity where they can sense each other’s Bluetooth connections. A will send B an RPI and B will send A it’s RPI.
Each handset stores a growing list of RPIs it received from other handsets.
Determining Risky Contacts
When the owner of a handset receives a positive test result for COVID-19, that owner will have the option to self-identify in whatever application is using this protocol. Then the application will:
- Gather the last N used Daily Tracing Keys (default to maybe the last 14)
- Send these DTKs to a remote server
At this point, all other handsets are able to download these DTKs. Now remember, given any DTK, you can compute all possible 144 RPIs from that DTK without needing any other information.
So, if a handset receives a list of 14 DTKs from the remote server, that handset can compute all potential RPIs for that list of DTKs. This is 14 * 144 (2,016) possible RPIs. The handset now determines if one or more of those 2,016 RPIs are in its own list of RPIs that it received from other handsets in the last 2 weeks.
This is essentially doing a set intersection between the 2,016 derived RPIs from our infected subject and the set of all RPIs we received from other handsets.
The intersection of RPIs now represent precise windows of time that a handset was in close proximity to another handset where the owner has tested positive for COVID-19.
Here is a simplified graphic overview of how this process works:

Simulation
To simulate how this works I created a basic Python class that represents a single handset. Additionally, I created a Life class that simulates 2 weeks of life-living from a subject that will eventually test positive for COVID-19.
The pattern-of-life is very rudimentary, we assume the individual interacts with family in the morning, co-workers for most of the day, other random individuals at meals, errands, etc and back to family in the evening. Weekends are a mix of interacting with family, friends, and others.
The README will get you started if you want to run it yourself. When the simulation begins, we choose a random amount of family, friends, co-workers and others that you will interact with. The “others” category represents all the people the subject does not know, but interacts with at stores, gyms, etc.
The number of unique handsets increases for family, friend, and so on in an attempt to be a little realistic about who you have close and continuing contact with.
After it runs, a “report.txt” will be generated. The header of this report will show the chosen sizes of your groups:

I hard-coded the start date to be 13 Apr at 0700 AM ET.
Each interaction with a category of people chooses a handset at random from that group. Naturally this yields higher amounts of interaction with family compared to a larger group like “others.”
The other sections in the report shows what a single handset might show to its owner. Each handset report would not be able to be aggregated at a single location.
Additionally, the report is sorted descending by the number contact windows each handset had with the infected individual.
Taking the first handset report from the list, shows a high level of interaction with the subject:

Naturally, as we scroll down the report, other relation categories have fewer interactions with the subject:


Privacy
The protocol itself drastically reduces risk of re-identification. Rotating unique IDs that grow in cardinality for any given handset help mitigate risk. The rotating RPIs assist in providing much better granularity of risky contacts while also mitigating re-identification.
With that said, the upstream use of this protocol is the biggest risk.
Device and owner specific information should not be collected, ever. It’s “easy” to also collect device / user information especially in the step where DTKs are sent to a remote system. This would include handset data, GPS location information, and transport information (IP addresses, etc). This data can be joined and used to re-identify DTKs to specific people.
This protocol does not guarantee anonymity from other people that may receive a notification once the subject discloses an infection. Primarily because it is very likely someone might recall where they were on any date and time and narrow down the potential list of carriers to the subject that reported the positive test in the first place.
Generally, the protocol should be implemented in a way that ensures the owner of the upstream systems that collect DTKs are unable to identify specific individuals. This protocol should more quickly enable better testing candidates and faster quarantines and does not replace the more specific location/trend analysis that public health professionals will have to do.

.png)
