Exploring NLP Part 2: A New Way to Measure the Quality of Synthetic Text

TL;DR
Multiple users have asked us about the quality of our synthetic text. With tasks ranging from intent classification to better speech recognition, users want to know whether they can bolster their datasets using our synthetic text. But how do we measure the quality of synthetic text? In this blog post, we give an overview of the types of text metrics that exist today. Then we present an innovation built on top of the work of Xiang et. al. that better aligns with our use case (and outperforms its predecessor on several datasets).
If you want to skip right to the code and replicate our experiments, feel free to visit our public research repo! We will be sharing our experiments from blog posts here from now on.
Overview of Text Metrics
A range of techniques are used to evaluate synthetic text. Here we discuss reference-based metrics that seek to characterize how closely synthetic text matches some reference text. Popular metrics in this space include BLEU and ROUGE, which are usually paired together (BLEU corresponds to precision and ROUGE corresponds to recall). Both metrics compute a score by determining how much the synthetic text and real text overlap. But what if the synthetic text and real text had minimal overlap? Consider the following example. The real text reads:
“It was really great hanging out with you today!”
and the synthetic text reads:
“I had an excellent time!”
The synthetic text would be given a score of 0, even though the synthetic text has similar semantic meaning to the original text. This mismatch led us to investigate other text metrics using embeddings, since Gretel wants to generate synthetic text that has the same semantic and grammatical structure of the original text, but also produces new text that has a low chance of exposing sensitive information found in the original text.
Other reference based metrics using BERT have been coming out in recent years. Two of the metrics we explored are BERTScore and BLEURT. BERTScore finds embeddings for each word in the real and synthetic texts, performs a pairwise cosine similarity metric on each real, synthetic word pair, and then performs a greedy matching on a matrix of the cosine similarity scores to generate a composite score. BLEURT on the other hand pre-trains and fine-tunes a BERT based regression model to provide scores. It is pre-trained twice on perturbed, synthetic text examples from Wikipedia utilizing several more traditional scores (such as ROUGE and BLEU). The first pre-training regimen is using the language modeling task usually done for BERT, while the second pre-training regimen focuses on natural language generation. After pre-training, BLEURT is then fine-tuned on human ratings of synthetic text. Using their code, you can fine-tune on any human ratings data you want.
Both of these scores have one major issue for Gretel: they require matched real/synthetic pairs of text. Our data generation process trains on the entire real data set, and we can produce as many synthetic examples as we want. Thus, there isn’t a correspondence between the synthetic and real examples. So what we need is a text metric that:
- Does not require a 1-1 real, synthetic matching.
- Does not require that the synthetic and real text contain the same words.
Our data generation process does not produce 1-1 pairings of real/synthetic examples. But it does generate a 1-1 pairing of real/synthetic datasets. Thus, we are able to compute metrics concerning the distribution of the data, which we already do in the synthetic quality report. This leads to our favorite text metric thus far.
Fréchet BERT Distance and Some Enhancement
Fréchet BERT Distance (FBD), inspired by the Fréchet Inception Distance that is used frequently to evaluate synthetic image generation in GANs, is a BERT based metric that evaluates the distance between distributions created by the real text embeddings and the synthetic text embeddings. Formally, assume that both distributions are multivariate gaussians. Let μᵣ and Σᵣ be the real mean and covariance matrices respectively and μₛ and Σₛ be the synthetic mean and covariance matrices respectively. Then the Fréchet BERT Distance between the real embeddings distribution and synthetic embeddings distribution is:
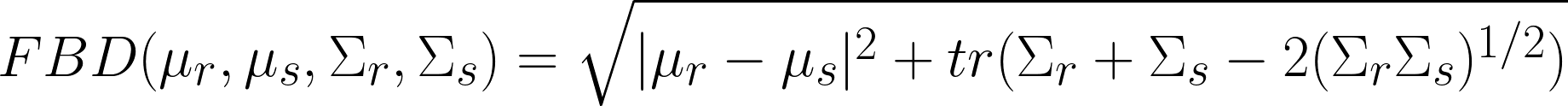
FBD fits our use case. It does not require a 1-1 real/synthetic pairing and it does not require a rigid overlap between the pair of texts. Moreover, it is quick to compute once you generate the embeddings. That speed is due to the assumption that the embeddings themselves generate a multivariate gaussian distribution, a simplifying assumption that seems to not deprecate results.
Users have tried to generate multiple kinds of text data. We’ve seen comments, reviews, doctor’s notes, etc. flow through our system. Some have even approached us with intent classification problems that require generation of synthetic conversational text. What all these have in common is that they operate on the document level. Word embeddings have been a fantastic breakthrough, but we want to compare the full text per record and not just the words contained in each text example.
Sentence Transformers (also known as SBert) is an architecture that takes the mean of the BERT embeddings for a document and then performs a fine-tuning task using cosine similarity to make sure the sentence embeddings are semantically meaningful. SBert has a library of different models to choose from that vary significantly in terms of efficacy and task alignment. You can find all of their models via HuggingFace.
We also want to make our metrics as easy to understand as possible. Getting a score comparing two multivariate gaussian distributions without any visuals is challenging for some to grasp. It may leave users wondering, “what is this metric really saying?” So we pair our version of FBD with a new metric we call Fréchet Cosine Similarity Distance (FCSD).
After we take sentence embeddings of both the real text and the synthetic text using SBert, we then take the mean of the real text embeddings. This provides an anchor point for us to generate cosine similarity scores. We take the cosine similarity between the real text and the real mean to form one distribution and do the same with the synthetic text and the real mean.
This gives us a distribution we can visually present to our users after we generate the FBD score. And we can also calculate the Fréchet Distance between the two cosine similarity distributions, thus giving us another score to present to our users.
Experiment: Methodology
Even if we have a new idea for a text metric, we want to make sure that it, at the very least, is as good or improves upon its predecessor. Thus, we replicated the experiments done in Assessing Dialogue Systems with Distribution Distances by Xiang et. al., the paper that first introduced the FBD metric, and tested the results against our two new metrics: FBD and FCSD utilizing SBert embeddings.
For the original FBD metric, Xiang et. al. utilized either BERT or RoBERTa to perform the embeddings. According to them, RoBERTa outperformed BERT as an embedding for FBD. Thus, we decided to use the RoBERTa implementation for our experiments. For the SBert embeddings, there were many models to choose from. We chose 12 of the top performing models as of August 2021. The researchers who maintain SBert are frequently generating new pre-trained models, so the top models available today may not be the same models shown at the time of the experiment. The models we tested are:
The datasets used were the same ones described in the paper. They are dialogue query and response datasets with human annotations. The goal of this evaluation is to see which metric most correlates with the human annotations of these datasets. If a metric is highly correlative, that means it is performing well. Just like the paper, we calculate both the Pearson and Spearman correlation coefficients for all datasets, comparing the automated metric against human annotations. We omit one dataset used in the paper, Persona(M), due to not understanding which ratings were used to perform the correlations found in Xiang et. al. The names of the datasets we did use are below:
Just to note, all experiments were originally run on a CPU (and only took a couple of hours to run!). If you would like to use a GPU, you may need to tweak the code a bit.
Experiment: Results
From our results (which you can find in this Google Sheet), we can see that FBD using Sbert’s `nli-roberta-base-v2` model outperformed the original FBD metric on 6 different measures. On the measures it did not outperform the original FBD metric, it still did better than the other SBert models on 3 of those measures and performed competitively with the original FBD metric. Moreover, although FCSD did not perform as strongly across the board, the metric performed most consistently when using `nli-roberta-base-v2` based embeddings. Note that this table only showcases the 4 best performing models. You can run the rest of the experiments using our notebook.
Discussion & Next Steps
This blog post presented innovations on top of the Fréchet BERT Distance developed by Xiang et. al. It fits extremely well with our use case and outperforms its predecessor in our analysis. We documented our thought processes behind the development of this metric, the methodology we replicated from the original FBD paper, and the results from our top performing models.
We would be remiss if we did not share some limitations and challenges. Yeh et. al. showcases several metrics that categorically outperforms FBD. However, many of those metrics require fine-tuning, meaning they would need more time to calculate than FBD. Thus, we chose to build on FBD because it provides our users with a quicker, more seamless experience. Moreover, although we replicated the analysis done by Xiang et. al., we note that their use case is different from ours. They use a combination of query and response, but in our product we would only use the “response” portion. Thus, we will also be doing an internal evaluation of the new metric.
In our next blog post in the series, Exploring NLP Part 3, we will utilize our new metric to evaluate some language models. Specifically, we will be benchmarking our own synthetic data generation model against some transformer based models and possibly some other architectures. Hope you come back and enjoy!
Here’s what we were reading
- Assessing Dialogue Systems using Distribution Metrics (original FBD paper)
- A Comprehensive Evaluation of Dialogue Evaluation Metrics
- BERTScore
- BLEURT (connects to GitHub repo, blog post, and paper)
- Sentence-BERT
- RoBERTa

