Synthetic Time Series Data Creation for Finance
Introduction
In this study, we discuss the creation of high-quality synthetic time-series datasets for one of the largest financial institutions in the world, and the methods we designed to assess the accuracy and privacy of our models and data. The temporal, ordered nature of time series data can help track and forecast future trends, which unsurprisingly, has enormous utility for business planning and investing. However, due to regulations and the inherent security risks that come with sharing data between individuals and organizations, much of the value that could be gleaned from it remains inaccessible. Here, Gretel’s work demonstrates that synthetic data can help close this gap while preserving privacy. By generating synthetic time-series data that are generalizable and shareable amongst diverse teams, we can give financial institutions a competitive edge and the power to explore a whole new world of opportunities.
Developers can test our methods by opening up our example Colab Notebook, clicking “Run All”, and entering your API key to run the entire experiment, or by following along with the 3-step process outlined below!
The Test Dataset
For this experiment, the bank’s data science team provided a time series dataset containing customer account balance information over time, which spans 6 columns and approximately 5500 rows. There is a time component in the `date` field, and a set of trending account balances that must be maintained across each `district_id`.

Step 1: Create a pipeline to synthesize the time series dataset
In this step, we will create a simple pipeline that can be used to de-identify the time series dataset, and then create a synthetic model that will generate an artificial dataset of the same size and shape. Below is a diagram of the pipeline we will use to generate and test our time series model.

To de-identify the data, we use Gretel.ai’s Transform API with the configuration policy below to randomly shift any dates and floating point values in the data. To ensure consistent shifts for each district, we define the `district_id` identifier as a seed value. This step provides strong initial guarantees that a synthetic model will not memorize repeated values in the data.
We then train a synthetic model on the de-identified training dataset, then use that model to create a synthetic data set with the same size and shape of the original data. For this, we will use Gretel’s “smart seeding” task, which conditions the model with the `date` and `district_id` attributes specified below and effectively asks the model to synthesize the remaining data.
Step 2: Assess the accuracy of the data
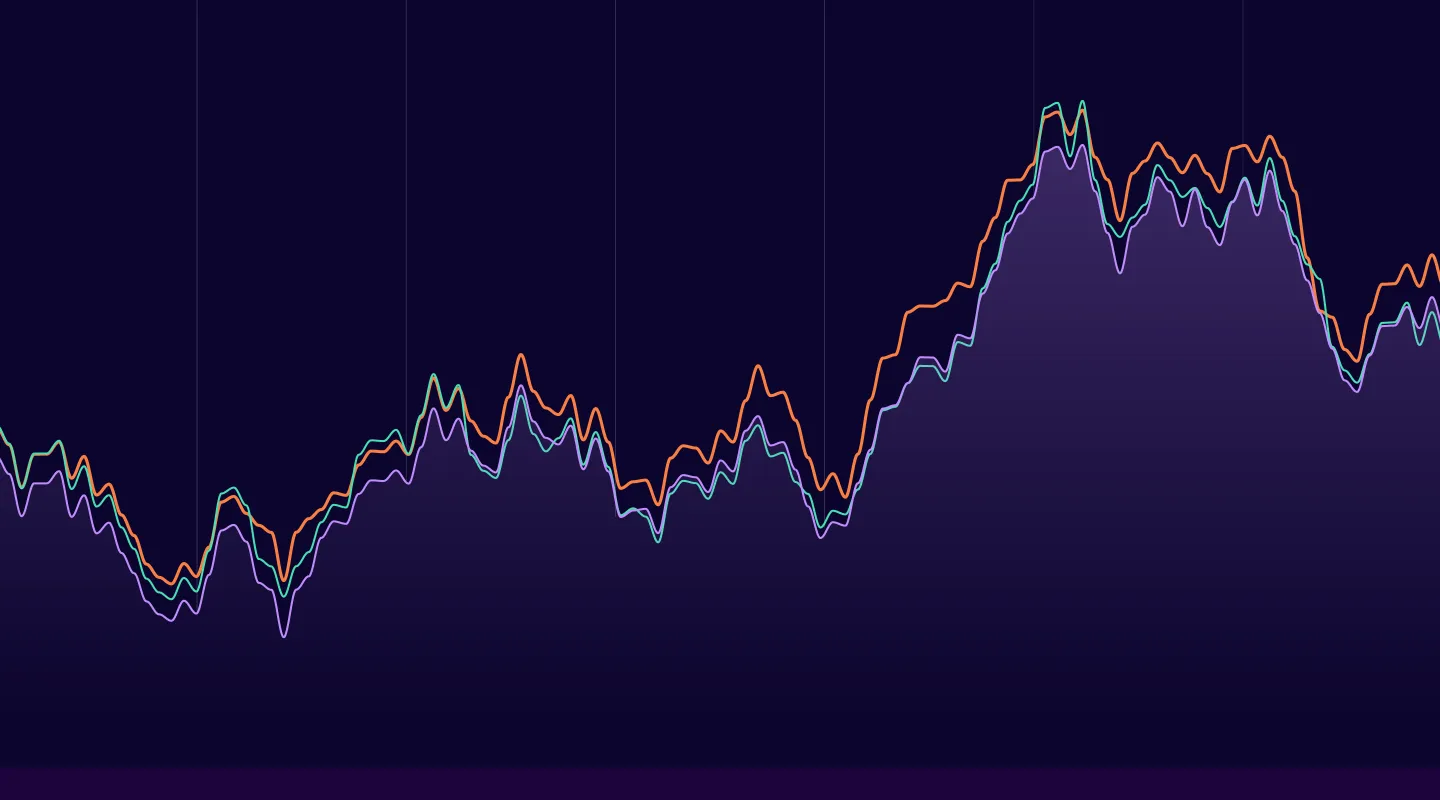
Next, we need to test our model’s accuracy, which starts with running a quick sanity check using a comparison of time series distributions for a district in our dataset. Here, Gretel’s synthetic quality score report (viewable in the notebook) is helpful for assessing the model’s ability to learn correlations in the data. Below, you can see our synthetics are in line with the original dataset. Success!

To tackle the tricky problem of assessing the quality of our synthetic time series dataset, the bank’s team fitted an ARIMA model to both the synthetic and original datasets. This allowed us to measure how well each dataset captured seasonality in the data. (Note: our POC notebook uses the SARIMAX model in the statsmodels package, which includes a multiplicative seasonal component similar to the modified ARIMA model used by the bank’s team.)
To train the SARIMAX models, we used district_id = 13 and ran an experiment on each available target variable (this generated four target variables). For evaluating our model’s prediction accuracy i.e. the root-mean-square error (RMSE), we used the last year in the dataset (1998) as our validation. The available years prior were used for training the model. All other parameters in the SARIMAX model were left at their default settings, except for those provided by the bank’s team. Namely, the order = (0,1,1) and the seasonal_order = (1,1,0,12). Lastly, we made sure to order the data by date for each run.
The images below are the RMSE results for each config used and the original dataset. The goal is to minimize RMSE. Here, it’s notable that for many synthetic data runs, we outperformed the real data on at least one target variable. In particular, look at runs 17, 18, 19, and 20, where we controlled for the float precision of the columns before generating synthetic data. This control especially helped with runs 19 and 20, where we did significantly better than the real data on 3 out of 4 variables. Moreover, run 20 includes the suggestion of removing net_amt from the synthetic data generation, since it’s a derivation of credit_amt and debit_amt, and thus adds needless complexity to the process. Runs 20Priv and 20SDKPriv both turned on privacy settings with all the improvements described above.

The takeaway: optimal synthetic configurations can, in some cases, outperform the real-world data on our machine learning model by better minimizing RMSE.
Step 3: Assess the privacy of the artificial data
Finally, after creating our synthetic model and dataset, we can assess the privacy of our artificial dataset. Let’s compare our transformed and synthesized dataset to the original training dataset.

This notebook highlights a new feature in Gretel Synthetics called Privacy Filtering, which provides a form of armor to cover synthetic data weak points often exploited by adversarial attacks. For example, synthetics that are too similar to the original data can lead to membership inference attacks as well as attribute disclosure. Another serious privacy risk arises when you have synthetic ‘outlier’ records, particularly when they’re similar to outlier training records. To combat both scenarios, we created Similarity and Outlier filters, which can both be dialed to a specific threshold based on the desired level of privacy. In this study, the use of Gretel’s Similarity Privacy Filter removed all synthetic records that were duplicates of training records.
To take things a step further, one method for ensuring the privacy of every record in the original dataset is to enable `differential privacy,` where we add some statistical noise while training the synthetic data model. Intuitively, a model trained with differential privacy should not be affected by any single training example or small set of training examples in its dataset. This process involves changing the optimizer that generates a well-fit synthetic model, but it requires a large number of records (typically >50k) to maintain the privacy of each record. For this reason, turning on differential privacy in the config wouldn’t provide useful synthetic data while also maintaining a high standard of privacy.
Conclusion
In this POC, we successfully demonstrated that Gretel’s synthetic data can be as accurate, and in some cases even surpass that of real-world data used for machine learning classification tasks, while also providing strong privacy guarantees required to allow sharing inside a financial institution.
If you’re interested in building your own synthetic time-series datasets, you can sign up to Gretel for free. When you do, please feel free to share your results with our Slack Community. We’d love to hear what you’re working on!
Contributors
Alex Watson, Daniel Nissani, Amy Steier, Lipika Ramaswamy, Kendrick Boyd - Gretel.ai.


