Anonymize tabular data to meet GDPR privacy requirements

The European Union’s General Data Protection Regulation (GDPR) and similar privacy regulations require businesses to safeguard the personal data of their users. In combination with other privacy-enhancing technologies, synthetic data can help companies follow GDPR standards and significantly reduce risks associated with handling sensitive data.
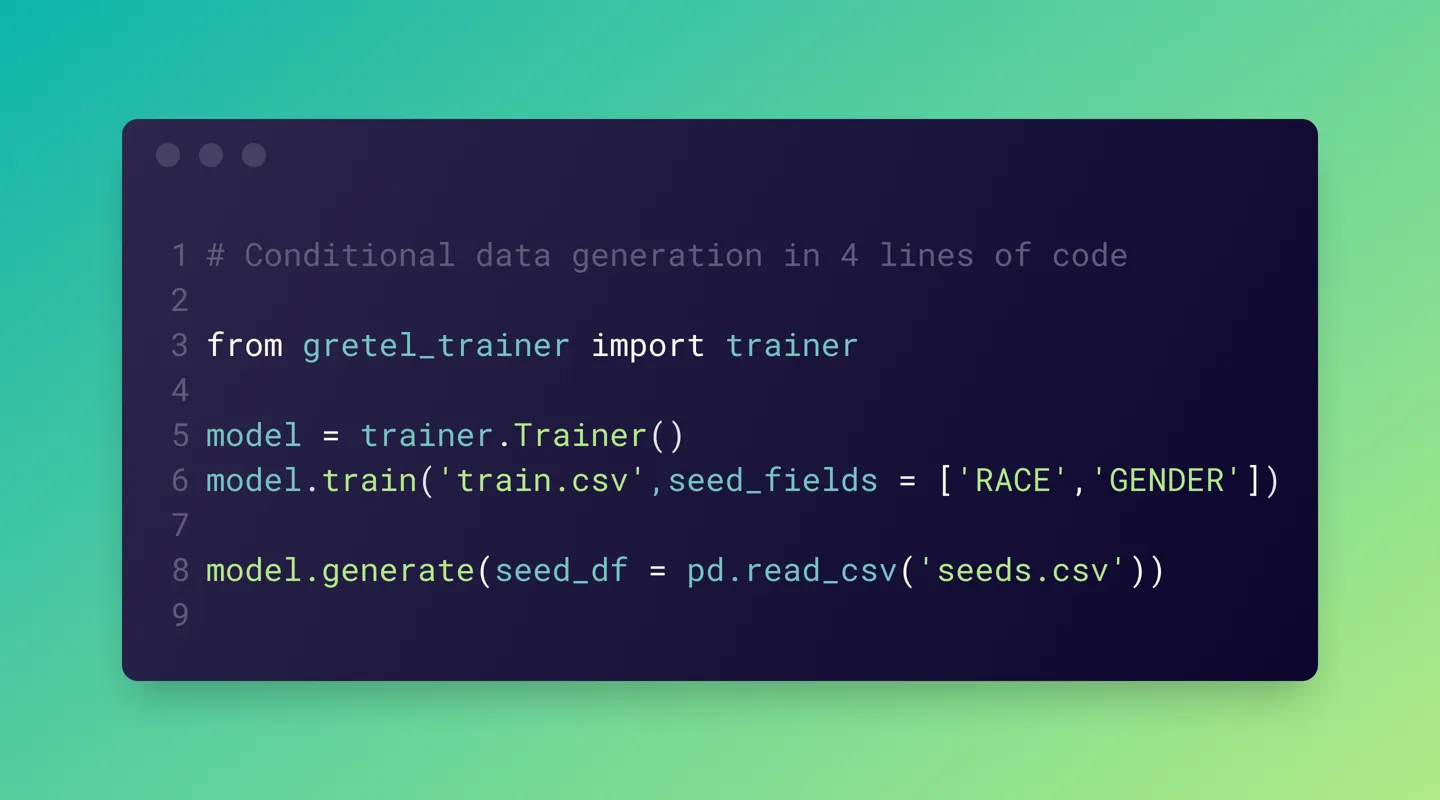
Let’s walk through how you can use Gretel’s Transform and Synthetics APIs to anonymize three different types of sensitive datasets with a single, customizable policy.
You'll learn how to:
- Set up a development environment
- Anonymize datasets using Gretel or your own cloud
- Modify data transformation and synthetics policies
- Create accurate and private synthetic versions of sensitive data
- Evaluate the anonymized data and synthetic data quality reports
Synthetic data as an alternative to real-world data.
GDPR Recital 26 defines anonymous information as information that “does not relate to an identified or identifiable natural person.” To be truly anonymized under the GDPR, personal data must be irreversibly stripped of sufficient elements to the point that the individual can no longer be identified.
Multiple academic and real-world examples have demonstrated that simply removing personally identifiable information (PII) such as names, credit card numbers, and addresses isn't sufficient to anonymize data. As no records in a synthetic dataset are based on a single person, synthetic data models inherently reduce the likelihood of singling out an individual, linking records about an individual, or inferring information about an individual. To learn more about how synthetic data can mitigate GDPR risk, check out our in-depth guide to the GDPR and synthetic data.
Let’s get started. 🚀
Note: This tutorial was created and run using Gretel’s cloud service, using an NVIDIA T4. For optimal data accuracy, we’ll use the Gretel ACTGAN model, which requires a GPU. For faster speeds, but slightly lower accuracy, you can use Gretel Amplify, which doesn't require a GPU.
Access the GDPR workflow notebook
Visit the Gretel Console and sign up or log in for easy access to the GDPR workflow notebook. With our use case cards, you can quickly set up projects that have configurations and steps optimized for the problems you’re solving, such as anonymizing data to meet GDPR standards.

Selecting the GDPR use case card provides two options for using our GDPR workflow. You can either:
- Go to the `gdpr-helpers` Github repository, and use the Python library as shown in our sample notebook; or
- Run the same notebook end-to-end in Google Colab.
We assume you’re taking the first option in the following steps, though you can follow the same code in Google Colab.
Set up a development environment
Your first step is to download Gretel’s `gdpr-helpers` repository, which includes the `gretel-client` library.
In a terminal:
This example uses the Gretel Cloud service to create synthetic data. If you selected the GDPR use case card, it provides an option to copy your Gretel API key. Otherwise, follow these directions to find your key. If you wish to run in your own cloud and synthesize data without it ever leaving your environment, follow the steps in the developer docs to install and configure Docker with GPU support.
For convenience, we recommend using the Gretel client on the command line to store your API key on disk. This step is optional; the `gdpr-helpers` library will prompt you for an API key if one can't be found.
Anonymize datasets using Gretel or your own cloud
We'll anonymize three example datasets, included with `gdpr-helpers`. The three datasets have a variety of dimensions, and include different types of data.
- Google Meet logs - 59 columns x 6,407 rows.
- E-commerce consumer product group (CPG) bike orders - 24 columns x 16,519 rows.
- Electronic health records - 22 columns x 2285 rows.
To run on your own datasets, change the `search_pattern` in the code below to point to CSV files in a folder on your filesystem. You can also update the Gretel Transform and Synthetics configurations (we’ll cover this in the next section). To anonymize sensitive data in your own cloud without sending any data to Gretel APIs, set “run_mode” to “hybrid.”
Create a new file, named “anonymize_files.py,” in the cloned repository, and put the following code in it:
Fine-tune data transformation and synthetics policies
You may wish to customize the data transformation policies. For example, you may need to replace detected PII with fake versions, or add a field that wasn't detected by Gretel’s named entity recognition (NER) APIs. To do this, you can modify the base `transforms_config.yaml` template using any of the available transforms in our docs. Often, a single `transforms_config.yaml` can be used across your entire organization and modified to support any number of company or application-specific fields.
By default, the template replaces detected email addresses with fake email addresses that come from a `foo.com` domain. If you wish to encrypt PII in place instead of replacing it with fake data, you can make the following change. Open the `./src/config/transforms_config.yaml` in your favorite editor and update the YAML:
(Example: Update Gretel’s transform config to encrypt PII versus using fake values)
From:
To:
Create accurate and private synthetic versions of sensitive data
After you have made any updates or changes to the base configuration, you can use your script, `anonymize_files.py`, to anonymize all of the files matching the search pattern you defined. By default, the anonymization workflow uses Gretel ACTGAN, a generative model with advanced accuracy and privacy settings.
For faster performance or to run in your own cloud without requiring a GPU, you can change the `synthetics_config.yaml` to use Gretel Amplify, a statistical model, with the following change:
(Example: Update the Gretel Synthetics config to use a fast, CPU-based generative algorithm)
`synthetics_config="synthetics/tabular-actgan"`
To:
`synthetics_config="synthetics/tabular-amplify"`
Review the anonymized data and quality reports
Let’s go ahead and run the Python program to anonymize the datasets. The gdpr-helper library will create three artifacts for each dataset that it anonymizes. By default, they'll be written to the `artifacts` directory in the following format:
- [dataset-name]-synthesized_data.csv - this is the fully anonymized, synthetic dataset.
- [dataset-name]-anonymization_report.csv - an html report with a complete log and history of all anonymization steps performed, which includes anonymization and privacy scores.
- [dataset-name]-transformed_data.csv - created by the first step of the process where any PII is detected and removed, or de-identified. This file shouldn't be used for production but is helpful to test and debug any changes to the transform report.

You have now completely anonymized the set of three sample datasets! For next steps, try anonymizing your own data. If you have any questions about this guide, or anonymizing data to meet compliance standards such as GDPR, CCPA, and others, please feel free to contact us inside the Synthetic Data Community we’re hosting over on Discord or at hi@gretel.ai.

.png)