Transforms and Synthetics on Relational Databases
Introduction
In a recent blog we walked you through how to use transforms directly on a relational database while keeping the referential integrity of primary and foreign keys intact. In this blog, we’ll simultaneously step you through both our new streamlined version of our multi-table transform notebook as well as our new multi-table synthetics notebook. The notebooks share much of the same process flow and can each be used independently or in tandem. As shown in the image below, there are three main flows you can take through Gretel when anonymizing data:
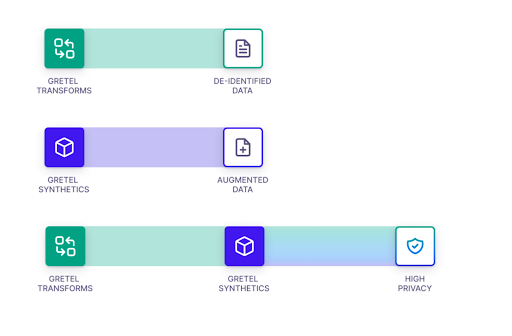
If you’re interested in just de-identifying data for a pre-processing or demo environment, then the transform notebook is the way to go. If you want to augment your data or if you intend to run a statistical or ML analysis on your data, then the synthetics notebook is the way to go. However, if you’re looking for the highest level of privacy, then the use of both notebooks is in order. The transform notebook is run first to remove PII and other sensitive information from the database tables. The synthetics notebook is then run to add another layer of protection and enable the creation of more or less records than in the original dataset. You can follow along with our Gretel multi-table notebooks located here or here:
Transform Notebook
Synthetics Notebook
Our Database
The relational database we'll be using is a mock e-commerce one shown below. The lines between tables represent primary-foreign key relationships. Primary and foreign key relationships are used in relational databases to define relationships between tables. To assert referential integrity, a table with a foreign key that references a primary key in another table should be able to be joined with that other table. Below we will demonstrate that referential integrity exists both before and after the data is either transformed or synthesized.

Gathering Data Directly From a Database
After cloning the multi-table repo and inputting your Gretel API key, we first grab our SQLite mock database from S3. In the transform notebook we use the original “ecom” database. However, in the synthetics notebook (as shown below) we’re using the “ecom_xf” database which is actually the final results of having first run the transform notebook on “ecom”. Both notebooks create an engine using SQLAlchemy. We then use that engine to gather data, and crawl the schema to gather primary and foreign key information.
These notebooks can be run on any database SQLAlchemy supports such as PostgreSQL or MySQL. For example, if you have a PostgreSQL database, simply swap the `sqlite:///` connection string above for a `postgres://` one in the `create_engine` command.
Take a Look at the Data
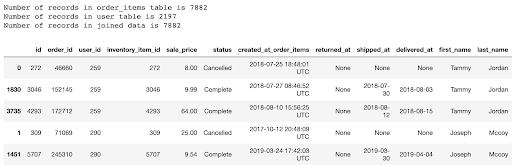
Both notebooks then take an initial look at the data by joining the order_items table with the users table using the user_id.
Below is the output (not all fields returned are viewable in the snapshot). Note how every record in the order_items table matches a distinct record in the users table. A primary goal of both notebooks is to show how we can run transforms or synthetics on a relational database and maintain these relationships.
Defining Configurations
Both transform and synthetic models require configuration setup to define how the models will be built. In transforms, policies are built which specify how PII or sensitive information is to be de-identified. For example, you could choose to replace all names with fake names or to offset every date by a random number of days. See our documentation for more information on how to set up transform configurations. In our multi-table transform notebook, we specify the location of policies as shown in the following code snippet. Note that not all tables in the database may require transforms.
In synthetic models, we use configurations to specify the hyperparameters used in the training. We have a variety of configurations to choose from depending on the characteristics of your dataset. Below we show how the default configuration is grabbed and assigned to each table in our synthetic notebook.
Training and Generating Data
In both notebooks, we then proceed to train models, generate data and align the primary and foreign keys. Behind the scenes, all training and generating is done in parallel with logging output letting the user follow the progress. The code in the transform notebook is:
While the code in the synthetic notebook, looking very similar, is as shown below. Note the synthesize_tables command also returns the models that were created so that later they can be used to view the synthetic performance reports.
Take a Look at the Final Data
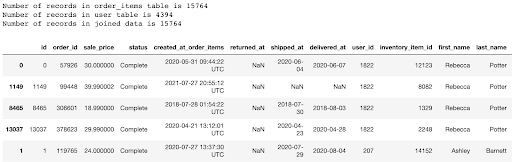
To view the final data in either notebook, we again take the same join on the order_items and users table that we did on the original data, but now applied to the new data. Once again, each record in the order_items table matches to a distinct record in the users’ table. Below we show the final data from the synthetics notebook:
In the synthetics notebook, you can also then take a look at the synthetic performance report for any of the tables with the following code:
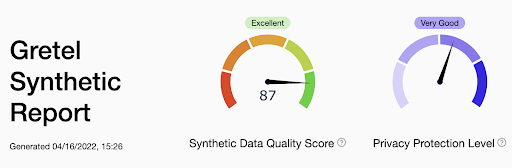
Below we show the header of the synthetic performance report for the table “users”. As you can see, we do quite well.
Load Final Data Back into Database
To wind things up, the last step in both notebooks is to now load the final data back into the database. In the transform notebook, we save the new data to “ecom_xf” using the schema in “ecom”, and in the synthetics notebook (as shown below) we save the new data to “ecom_synth” using the schema from “ecom_xf”.
Conclusion
As demonstrated above, the Gretel multi-table transform and synthetics notebooks are simple but powerful ways for anonymizing a relational database. Depending on your use case, you can use the notebooks independently to de-identify relational databases for testing environments (Transform) or to anonymize and augment data while maintaining statistical integrity (Synthetics); or you can use them together for maximum privacy protections. Whichever route you choose, the referential integrity of the primary and foreign keys will remain intact. With synthetics, you are also ensured that the ratio of new table sizes is a perfect reflection of the original data. Thank you for reading! Please reach out to me if you have any questions, amy@gretel.ai.


