Transforms and Multi-Table Relational Databases

Intro
The ability to share private, de-identified data is a rapidly growing need. Oftentimes, the original non-private data resides in a multi-table relational database. This blog will walk you through how to de-identify a relational database for demo or pre-production testing environments while keeping the referential integrity of primary and foreign keys intact.
You can follow along with our Gretel Transform notebook:
Our Database
The relational database we'll be using is a mock ecommerce one shown below. The lines between tables represent primary-foreign key relationships. Primary and foreign key relationships are used in relational databases to define many-to-one relationships between tables. To assert referential integrity, a table with a foreign key that references a primary key in another table should be able to be joined with that other table. Below we will demonstrate that referential integrity exists both before and after the data is de-identified.

Gathering Data Directly From a Database
After installing the necessary modules and inputting your Gretel API key, we first grab our mock database from S3, and then create an engine using SQLAlchemy:
This notebook can be run on any database SQLAlchemy supports such as PostgreSQL or MySQL. For example, if you have a PostgreSQL database, simply swap the `sqlite:///` connection string above for a `postgres://` one in the `create_engine` command.
Next, using SQLAlchemy's reflection extension, we gather the table data.
We then crawl the schema and produce a list of relationships by table primary key.
Take a Look at the Data
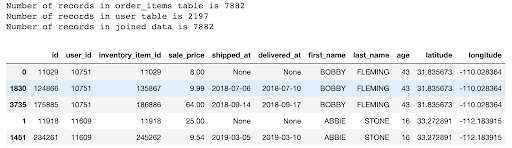
Now let's join the order_items table with the users table using the user_id.
Below is the output. Note how every record in the order_items table matches a distinct record in the users table. A primary goal of this notebook is to show how we can run transforms on the tables in this database and maintain these relationships.
Define Our Transform Policies
Now we need to define a transform policy for any table that contains PII or sensitive information that could be used to re-identify a user. We won't include a transform for any of the primary/foreign key combinations, as we'll be handling those separately. Let's take a look at the transform policy for the users table.
Within the "rules" section, we define each type of transformation we want, each one beginning with "- name". We start by replacing any field classified as a person’s name or email address with a fake version. Note, we chose to leave several of the location fields as is, such as "state" and "country,'' since it's public knowledge that this database is about user ecommerce transactions in Arizona. We then transform the "created_at" timestamp using a random date shift. And finally, we transform the numeric fields of age, latitude and longitude with a random numeric shift. Note, we did not transform "id" because it is a primary key that matches a foreign key. We will have special processing for primary and foreign keys later that ensures referential integrity is maintained.
Each policy should reside in its own yaml file and the locations for each are made known to the notebook as follows:
Model Training and Initial Data Generation
We first define some handy functions for training models and generating data using the policies we defined above.
Now that we have these functions defined, we can easily run all the training and generation in parallel in the Gretel Cloud. You can find the details of how to monitor this process in the notebook code here. The key API call for checking a model status is as follows:
The value of a model status begins with "created", then moves to "pending" (meaning it’s waiting for a worker to pick it up). Once a worker picks it up, the status becomes "active". When the job completes, the status becomes "completed". If there was an error at any point along the way, the status becomes "error". Similarly, the key API call for checking generation status (all the same valid values) is:
Note "model" is returned by the above "create_model" function and "rh" (record handler) is returned by the above "generate_data" function.
Transforming Primary/Foreign Key Relationships
To ensure referential integrity on each primary key/foreign key table set, we will first fit a scikit-learn Label Encoder on the combined set of unique values in each table. We then run the Label Encoder on the key field in each table in the set. This both de-identifies the keys as well as serves to ensure referential integrity, which means a table with a foreign key that references a primary key in another table should be able to be joined with that other table. The code to accomplish this is shown below.
Take a Look at the Final Data
We will now show the same join on the order_items and users table that we did on the original data, but now on the transformed data.
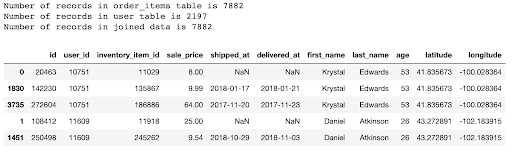
Once again, each record in the order_items table matches to a distinct record in the users’ table.
Load Final Data Back into Database
To wind things up, the last step is to now load the final transformed data back into the database.
Conclusion
We've shown how easy it is to combine direct access to a relational database with Gretel's Transform API. We’ve also demonstrated how large multi-table databases can be processed in parallel in the Gretel Cloud. And finally, we've demonstrated a technique for ensuring the referential integrity of all primary/foreign key relationships. Coming soon, we'll show you how to accomplish all of this using Gretel Synthetics.
Thank you for reading! Please reach out to me if you have any questions at amy@gretel.ai.