Gretel GPT Sentiment Swap
Here at Gretel, we are helping businesses fine tune large language models (LLMs) on their own unique data. Whether your goal is to diversify, balance, or fully synthesize a natural language dataset, our Gretel GPT API can streamline your task using commercially viable models, which can run in Gretel’s managed cloud service or entirely within your own private environment.
In this blog post, we use Gretel GPT to fine tune a multi-billion parameter LLM to generate product reviews of a specified sentiment. The goal? To enhance sentiment analysis training sets, especially in areas where certain sentiments are sparse. By doing so, we can more robustly train sentiment classifiers, optimizing their performance in discerning customer sentiments within product reviews.
This approach isn’t limited to product reviews; it’s equally effective for improving the detection of toxic or abusive language on your platform. By fine tuning the Gretel GPT model with your own data, you can rapidly generate high-quality labeled examples. This not only reduces the time needed but also significantly cuts costs compared to traditional data collection and manual labeling methods.
Let’s go 🚀
🫣 A sneak peek at what we’re building
By the end of this post, we will have a fine-tuned LLM that swaps the sentiments of product reviews. For example, suppose we have a negative review about the game Madden NFL 2001. Conditioned on this review, our fine-tuned LLM will swap the sentiment as follows:
Input Review: I do not recommend this game because I think you're better off buying Madden 2000! This game has bad graphics and there is no gameplay.
Output Review: I'm a big fan of Madden NFL 2001, the game is awesome. The graphics are better than any other Madden I have ever seen. You will have a good time playing it.
In the above example, the input review provides negative feedback about the game’s graphics and gameplay, whereas the output review is enthusiastic about both of these characteristics. Positive feedback about other aspects of the game and/or the customer’s overall experience would also be acceptable output — so long as the sentiment-swapped review sounds like a plausible review about the same game.
It turns out that the above example is a real generation from an LLM that we fine tuned while creating this post! Continue reading to learn how you can build your own version using Gretel GPT.
👩💻 Follow along and code with us!
The code and data used for this blog post can be downloaded from the gretel-gpt-sentiment-swap folder in our public_research GitHub repository. If you only want to clone the code used in this post, you can use GitHub’s sparse-checkout functionality:
Next, install the project dependencies (preferably within a virtual Python environment):
Alternatively, if you’d rather not install any packages locally, you can follow along with this Jupyter notebook in Google Colab (note that the first job it runs takes a few hours to complete).
A note about reproducing our results
To reproduce all the results of this post, you will need to run three scripts — the first builds the fine-tuning dataset, the second submits the fine-tuning job to the Gretel Cloud, and the third uses the fine-tuned model to generate synthetic data. Each script has command-line options, with defaults set to the values we will use in this post. You can see all the options for a given script using the `-h` or `--help` argument.
Create your Gretel account
If you don’t already have one, create an account on the Gretel platform. Our developer tier comes with 60 credits (5 hours of free compute) per month and a 4-hour maximum runtime limit, which is enough for you to follow along and fine tune a model with us!
🎛️ Fine tuning an LLM with Gretel GPT
To build our sentiment-swapping LLM, we will fine tune Gretel’s efficient fork of MPT-7B using Gretel GPT.
The fine-tuning dataset
What about the fine-tuning dataset? This is one of the most important choices we need to make. For our particular use case, we need a dataset with the following properties:
- It should consist of product reviews in the form of unstructured text.
- Each review needs an associated sentiment classification or some other indicator of customer (dis)satisfaction with the product.
- Each product needs multiple reviews of varying sentiment to teach the model how to generate both positive and negative reviews about the same product.
- It should have at least ~5-10k examples for fine tuning — the more the better!
While it is generally quite challenging to find an existing dataset that satisfies all your requirements, the Amazon Customer Reviews dataset is almost exactly what we are looking for. It contains millions of product reviews across 46 distinct product categories. And importantly for us, each review has an associated star rating, which we will use as a proxy for customer sentiment.
To create our fine-tuning dataset, we will use the following fields:
- `product_id`: We will use this to group the reviews by product.
- `product_title`: This will be used in the prompt to provide context about the product.
- `start_rating`: As mentioned above, we will use this as a proxy for sentiment.
- `review_body`: This is the text we want our model to sentiment swap.
- `helpful_votes`: This is the number of users that found the review helpful. We will use this to select reviews that make it into our dataset.
In this blog post, we will build fine-tuning examples from the Video_Games_v1_00 subset of the full Amazon dataset, but you are free to pick a different subset (note that a larger subset will take more time to train and may not be fully covered by our developer tier). Our dataset creation code can be viewed in the create_dataset.py script, where we fetch the data subset from the Hugging Face Hub, clean the text, select reviews and group them by product, and construct fine-tuning examples, as described below.
Product review pairs
The fine-tuning examples will consist of product review pairs of opposite sentiment. For simplicity, we will focus on 5-star and 1-star reviews, which we associate with positive and negative sentiment, respectively.
Here is an example review pair:
Product Name: Super Mario Bros. Deluxe (Gameboy Color)
Number of Stars: 5
Review: WOW! Mario was good before but this is just awesome!! Finally Mario comes to Gameboy!!! THIS GAME ROCKS!!!!
Product Name: Super Mario Bros. Deluxe (Gameboy Color)
Number of Stars: 1
Review: I put this game in my gameboy and it does not even work! Do not buy unless you want a broken game.
For each review pair in the dataset, we will randomly select whether the positive or negative review is first. This will train the model to go both directions in sentiment — from positive to negative and from negative to positive. At training time, the model’s job will be to generate both reviews. At inference time, we will simply prompt the model with all the text in a review pair, excluding the content of the second review.
Pair selection metric
For products with many 1-star and/or 5-star reviews, how do we choose which reviews to pair? There’s no one right answer to this question, as it depends on your particular use case and dataset. We have implemented two possible pair selection metrics.
The first metric selects reviews with the most “helpful votes” from users that found them useful. The assumption is that reviews with more votes will generally be more coherent, relevant, and interesting than reviews with less votes. In cases where there’s a tie in votes, we randomly select one of the reviews. This selection metric runs relatively quickly and is therefore the default choice. You can view the associated code in this function of the create_dataset.py script.
For the second selection metric, our goal is to pair semantically similar reviews. We accomplish this by creating dense embeddings of each review using the sentence-transformers library. We then pair reviews with the highest cosine similarity. This selection metric is more computationally demanding than the default metric described above. After batching the reviews for efficiency, it takes about 10–20 minutes to pair the reviews on an M2 Macbook Pro. You can view the associated code in this function of the create_dataset.py script.
When running the script, you can change the pair select metric using the `--pair-metric` command-line argument, which can be either `helpful_votes` or `cos_sim`. For this blog post, we will stick to the default values for all command-line arguments:
Where to find the review-pair datasets
When you run create_dataset.py, the created dataset will be saved as a compressed csv file in the data folder inside this project’s root directory. Additionally, an associated “conditional prompts” file will be created, which contains test prompts for products that only have 1-star or 5-star reviews (i.e., products for which it is not possible to make a review pair). These conditional prompts will be used later to assess the quality of the generated reviews.
For convenience, we’ve already created datasets based on the `Video_Games_v1_00` (16,420 review pairs) and `Apparel_v1_00` (20,000 review pairs) data subsets using both pair selection metrics, which should be downloaded when you clone the code repository.
Submitting a fine-tuning job to the Gretel Cloud
With our dataset in hand, we’re ready for the easy (and fun!) part: fine tuning an LLM using Gretel GPT. We will carry out the fine tuning using the Gretel Cloud. To submit our fine-tuning job, we run the fine_tune_with_gretel_gpt.py script with default arguments:
This will create a Gretel Project named “gretel-gpt-sentiment-swap” and start our fine-tuning job. Within the project, a model will be created with a name that indicates which data subset and pair selection metric you chose. If you used the video game data subset, the model should take a bit over three hours to train.
You can monitor your job’s progress in the Gretel Console. Upon completion, a Synthetic Text Data Quality Report will be generated to assess how well the synthetic data captures the statistical properties of the training data. This quantitative report is incredibly useful for building confidence in the quality of your synthetic data, though sometimes nothing beats looking at some example generations yourself, which we will show you how to do next.
🤖 Generating sentiment-swapped reviews
Once our model is finished training and we’re happy with its synthetic data quality report, we can either use it to generate completely new sentiment-swapped review pairs, or we can prompt it to generate the opposite sentiment of provided reviews. We will take the latter approach.
As mentioned above, we will generate a sentiment-swapped review by prompting our fine-tuned model with a product review pair, excluding the second review.
For a concrete example, here’s a prompt that will generate a positive review for the game Jambo! Safari Animal Rescue on Nintendo DS:
Product Name: Jambo! Safari Animal Rescue - Nintendo DS
Number of Stars: 1
Review: The game has some really nice features, however it is so complex that my 8 year old had trouble playing it on her own.
Product Name: Jambo! Safari Animal Rescue - Nintendo DS
Number of Stars: 5
Review:
Submit a generation job to the Gretel Cloud
The file of conditional test prompts we created previously contains 100 conditional prompts similar to the above example. Using this file as our input conditional data source, we run the generate_sentiment_swapped_reviews.py script with default arguments to submit a generation job to the Gretel Cloud:
This script will fetch our default project and use the last model we trained (you can use a specific model using the `--model-id` argument) to create sentiment-swapped reviews based on our input conditional data source.
The script should take about 5-10 minutes to complete, after which it will save the model generations in the model-generations folder. Two files will be created: one compressed csv file that contains the raw model outputs (i.e., the generated reviews) and another plain text file with the complete product review pairs for inspection.
Inspect the results
Our conditional data source file prompts the model using both positive and negative conditional reviews. Let’s take a look at a couple review pairs from each category. In the examples below, the normal and bold fonts indicate the prompts and generations, respectively.
Product Name: Nintendo 3DS Cobalt Blue with Luigi's Mansion: Dark Moon
Number of Stars: 5
Review: This was present for my daughter, her's wore out. She loves the color lot's nicer than the picture. We ordered at Christmas time and it was her a few days before it was supposed to be.
Product Name: Nintendo 3DS Cobalt Blue with Luigi's Mansion: Dark Moon
Number of Stars: 1
Review: i ordered this and the seller didnt send the item. this is a scam. DO NOT ORDER. I wish there was something i could do about this!
Product Name: Castlevania: Circle of the Moon
Number of Stars: 5
Review: Had this game when I was younger and got another copy as a birthday present for myself. It was in great condition, shipped fast, and played wonderfully.
Product Name: Castlevania: Circle of the Moon
Number of Stars: 1
Review: I've never even been able to play this game because I can't even get it to load on my system. Very disappointing.
Product Name: Li-Ion Rechargeable Battery For PSP
Number of Stars: 1
Review: Very poor quality. Do not work well at all. Invest in something better.
Product Name: Li-Ion Rechargeable Battery For PSP
Number of Stars: 5
Review: It's not a bad battery, it works perfectly. It's the best quality for the price and it fits perfect on my PSP.
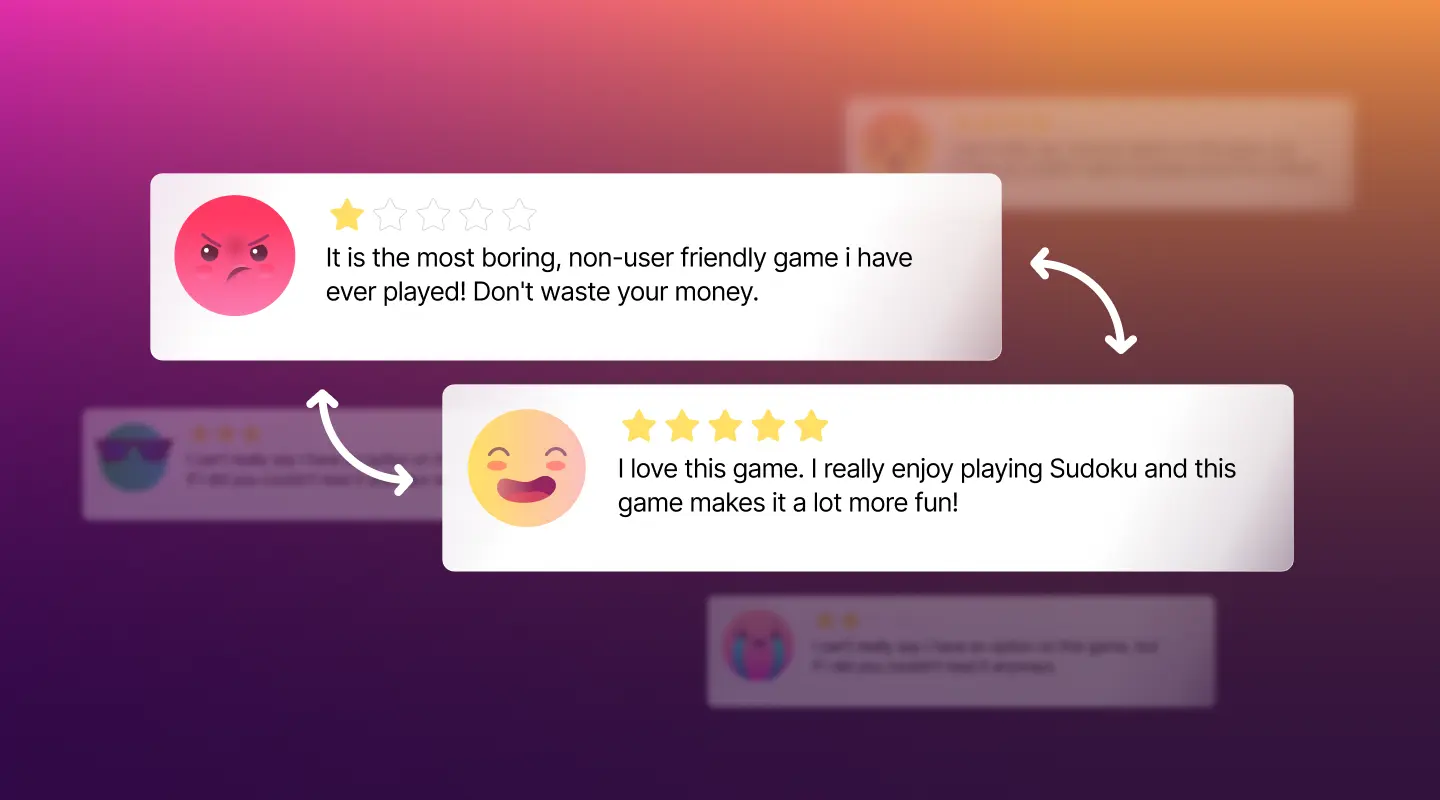
Product Name: Sudokuro: Sudoku and Kakuro Games - Nintendo DS
Number of Stars: 1
Review: it is the most boring, non-user friendly game i have ever played! Don't waste your money
Product Name: Sudokuro: Sudoku and Kakuro Games - Nintendo DS
Number of Stars: 5
Review: I love this game. I really enjoy playing Sudoku and this game makes it a lot more fun!
At quick glance, it looks like our fine-tuned model works well! The content of each generated review is relevant to the product mentioned in the prompt, and the review sentiments are swapped for all pairs. The model also captures the tone and informal writing style of the real reviews, including typos, words in all caps, and missing punctuation.
You can view all 100 sentiment-swapped review pairs based on our default script settings in the plain text file that was output by our generation script.
🪜 Next Steps
Pair semantically similar reviews
As a first next step, we recommend repeating the above exercise using the cosine similarity to select review pairs. How do the model generations differ from our default “helpful votes” pair selection metric? You can also try using a different data subset and/or combining subsets from the Amazon Customer Reviews dataset.
Sentiment swap “meh” reviews
For simplicity, we limited our fine-tuning data to 1-star and 5-star reviews. It’s also possible to include 3-star reviews or even all possible star reviews in your training set. You would need to put some thought into how to construct the training examples — for example, instead of review pairs, you might use a sequence of 1–5 star reviews for each product.
Explore more use cases
The workflow we followed in this blog post can be adapted to a wide range of domains and use cases. Indeed, with enough domain-specific data for fine tuning, Gretel GPT can help you conditionally generate realistic doctor’s notes, legal contracts, meeting transcripts, or even in-game banter between players in a chat app — just to name a few possibilities!
Sign up for free and start synthesizing data with Gretel.


