Conditional data generation in 4 lines of code
In part one of this post, we introduced the `gretel-trainer` SDK, an interface designed to be the simplest way to generate synthetic data.
In today’s post, we’ll walk through conditional data generation. Conditional data generation (sometimes called seeding or prompting) is a technique where a generative model is asked to generate data according to some pre-specified conditioning, such as a topic, sentiment, or using one or more field values in a tabular dataset.
Conditional generation is a method that you can use to generate additional labeled examples for machine learning training sets, at a fraction of the cost of traditional manual or human-generated labeling techniques. It can be a useful technique to address bias in data, such as in correcting class imbalances in patient data to provide fair and equitable healthcare.
Try out the code below, or follow along step-by-step with our notebook in Colab.
First, start with installing the `gretel-trainer` library. Next, sign up for a free Gretel account and grab an API key from https://console.gretel.ai.
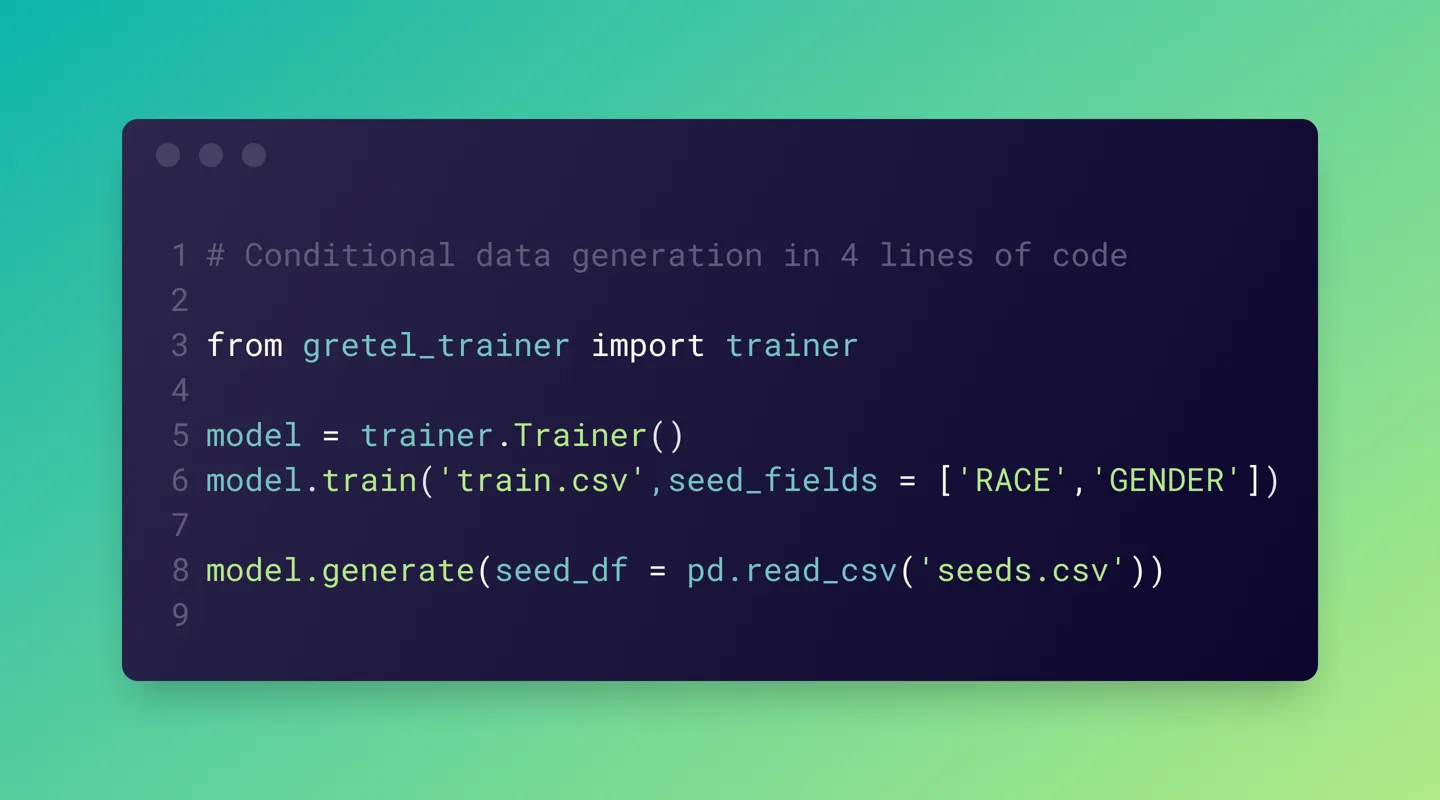
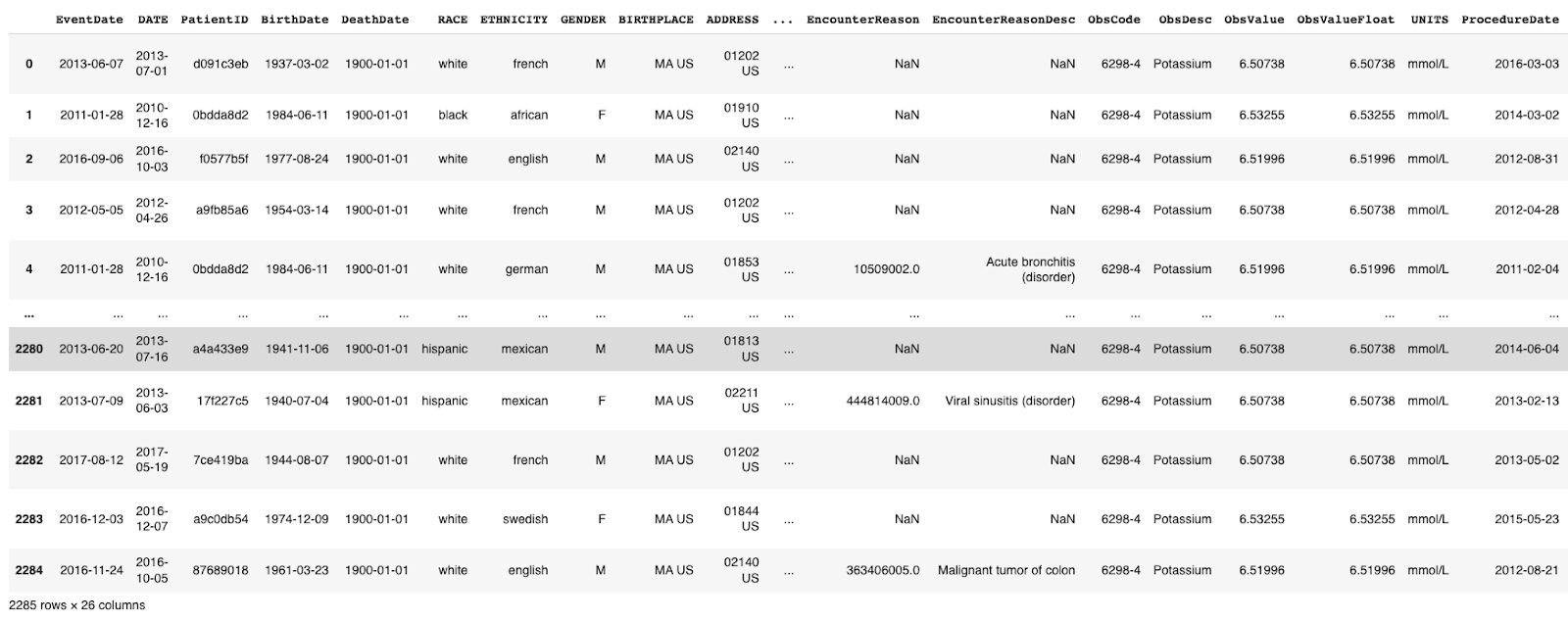
Below is the simplest path to conditionally generating tabular data. This code uses Gretel’s APIs to train a deep learning model on the popular MITRE synthetic patient record dataset, which includes demographic fields common to medical data.
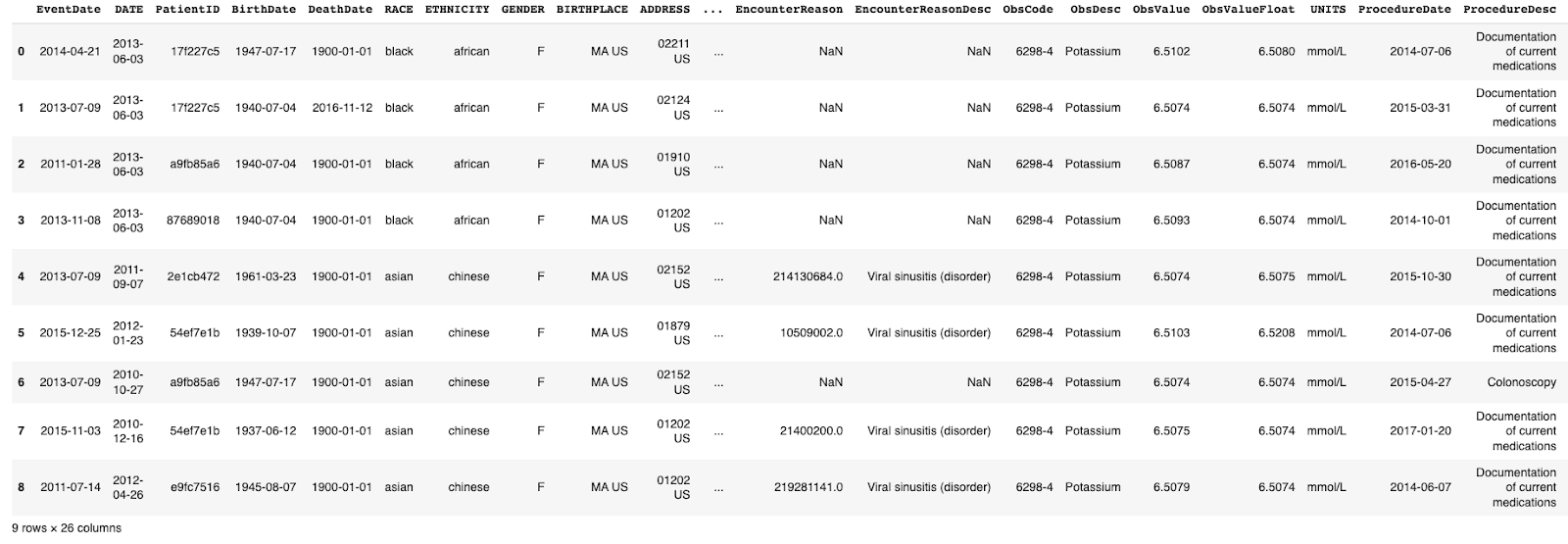
For this example, we'll use one of Gretel’s AI-based generative models and then sample 10 additional records that match predefined race, ethnicity, and gender column values.
Train our model on the patient records dataset, specifying the fields we wish to use for conditional data generation.
Sample new synthetic data from our model matching the predefined criteria.
Gretel-trainer uses Gretel’s fully managed cloud service for model training and generation. You can create state-of-the-art synthetic data without needing to set up or manage infrastructure and GPUs. Try running our Colab notebook, and for the next steps, try running on one of your own datasets or CSVs, or check out our Github to see advanced examples or to compare results across different models. Have questions? Ask for help on Gretel’s community Discord.


